
Installation de Rhasspy avec Jeedom, un assistant vocal Open Source et Free Software adapté à la domotique
5 juillet 2021Dans le cadre de mon stage au sein du G2ELab, j’étudie actuellement les assistants vocaux afin de rendre plus interactif et éducatif la gestion de l’énergie. J’évolue sur la plateforme de démonstration Prédis-MHI située au sein du bâtiment GreenER.
Dans cet article, nous allons apprendre à installer l’assistant vocal open source Rhasspy sur une RaspberryPi et à le connecter à Jeedom pour pouvoir gérer sa maison intelligemment. On introduira le sujet sur les assistants vocaux de manière générale et à la suite de l’introduction débute le tutoriel d’installation. Vous pouvez vous rendre directement au tutoriel en cliquant ici.
Introduction
Les assistants vocaux sont des outils, des services informatiques permettant un échange via une communication orale et audio entre des utilisateurs et leurs appareils connectés. L’usage est très utile dans la domotique et l’habitat intelligent qui « La domotique est l’ensemble des techniques de l’électronique, de physique du bâtiment, d’automatisme, de l’informatique et des télécommunications utilisées dans les bâtiments, plus ou moins « interopérables » et permettant de centraliser le contrôle des différents systèmes et sous-systèmes de la maison et de l’entreprise (chauffage, volets roulants, porte de garage, portail d’entrée, prises électriques, etc.). La domotique vise à apporter des solutions techniques pour répondre aux besoins de confort (gestion d’énergie, optimisation de l’éclairage et du chauffage), de sécurité (alarme) et de communication (commandes à distance, signaux visuels ou sonores, etc.) que l’on peut retrouver dans les maisons, les hôtels, les lieux publics, etc. ». [1]
Ces assistants qui ont comme leur nom l’indique pour but d’assister et permettent de faciliter la vie usagers en s’intégrant parfaitement dans l’environnement quotidien. Les assistants vocaux peuvent soit répondre à des questions simples que lui posent l’utilisateur (ex : « Quelle heure est-il ? », « Quelle est la météo à Grenoble ? », etc.) mais ils peuvent également effectuer des tâches et donner des ordres à des appareils électroniques connectés au réseau de l’assistant (ex : allumer une lampe, fermer les volets, jouer de la musique sur une enceinte, etc.).
Un assistant vocal est une interface homme-machine (ou homme-environnement) interactive qui permet d’acquérir un signal (reconnaissance vocale), de le traiter, et d’en renvoyer un autre (action à effectuer, réponse à l’humain via un haut-parleur)
Fonctionnement d’un assistant vocal par étape :
- L’utilisateur prononce un mot clé et « réveille » l’assistant. Ce mot clé utilise un algorithme interne de reconnaissance de schéma vocaux et ne nécessitent donc pas d’accès à internet. Ensuite un canal d’écoute s’ouvre et le contenu audio est transmis à la volée (stream).
- Dans bien des cas, si le traitement est réalisé de façon distante, une seconde vérification de la prononciation du mot-clé est faite côté serveur afin de limiter les déclenchements intempestifs.
- Éventuellement, et s’il a été préalablement enrôlé –c’est-à-dire si un apprentissage de ses caractéristiques vocales a été réalisé à partir d’échantillons de voix qu’il aura produits – le locuteur peut être identifié (speaker identification).
- L’utilisateur énonce sa requête et celle-ci est transmise aux instances de traitement. Il peut s’agir de serveurs distants, ou dans le cas d’un traitement local, de ressources matérielles embarquées dans l’équipement. La séquence de parole prononcée est alors automatiquement transcrite (speech to text).
- À l’aide de technologie de traitement automatique du langage naturel (TALN), la parole est interprétée. Les intentions du message sont extraites et les variables d’informations (slots) identifiées.
- Un gestionnaire de dialogue permet de préciser le scénario d’interaction à mettre en œuvre avec l’utilisateur en apportant le schéma de réponse approprié.
- Une réponse adaptée à la requête de l’utilisateur est identifiée et le cas échéant, des ressources distantes sont utilisées : base de connaissance publiquement accessibles (encyclopédie en ligne, etc.) ou par authentification (compte bancaire, application musicale, compte client pour achat en ligne, etc.).
- Les variables d’informations (slots) sont remplies avec les connaissances récupérées.
- Une phrase de réponse est créée et/ou une action est identifiée (monter les stores, augmenter la température, jouer un morceau de musique, répondre à une question, etc.).
- Cette phrase est synthétisée (text to speech) et/ou l’action à opérer est envoyée à l’équipement.
- La réponse et/ou la commande est mise en œuvre par l’équipement embarquant l’assistant vocal.
- L’assistant vocal repasse en veille.
Un assistant vocal n’est donc pas à proprement parler « intelligent ». Les éléments de connaissance proviennent de sources tierces : données en libre accès (encyclopédies en ligne), bases de données contenant des informations renseignées par l’utilisateur (son agenda, son carnet d’adresse, etc.), etc. [2]
Les assistants vocaux sont pourtant tous différents, ils dépendent tous des algorithmes et des logiciels utilisés pour les faire fonctionner. Chacun de ces programmes peuvent être différents : programme de détection du mot clé, la reconnaissance vocale effectué par des algorithmes de Speech To Text, le traitement des données faites par des algorithmes de Machine Learning appliquées à des base des données, la création de la commande ou action à effectuer, le calcul de la réponse à donner, et la traduction de cette réponse en action et/ou vocal par un Text-To-Speech.
Selon le créateur d’assistant vocaux, tout peut être créée par le créateur/développeur de l’assistant vocal (c’est le cas des GAFAMs) ou alors passer par des programmes déjà existants qui sont Open Source ou alors utilisable grâce à des API.
Comparatif entre les assistants vocaux libres et non-libres
| Type d’assistants vocaux | Les Assistants vocaux « non-libres« | Les assistants vocaux « libres » |
| Descriptif | Les Assistants vocaux « non-libres » les plus utilisés sont les assistants développés par les GAFAM (Google Assistant, Siri de Apple et Cortana d’Amazon -> liste non-exhaustive). | Les assistants vocaux « libres » sont des assistants vocaux qui peuvent être librement exploités ou à minima analysé (transparence du code). |
| La propriété (Libre ou privées, transparence, base de données) | Les assistants vocaux de cette catégorie-là appartiennent à des grands groupes du numérique (Google, Amazon, Apple, etc.), ils sont leur propriété et donc ne sont pas libre d’utilisation. Ces entreprises-là se veulent transparente sur le fonctionnement de leur assistant mais n’en reste pas néanmoins opaque sur le code source qui n’est pas exploitable ou analysable. De plus, ces grands groupes ont le net avantage de posséder des bases de données gigantesques leur permettant d’obtenir une qualité de produit très importante. | Les assistants vocaux de cette catégorie-là sont libres et permettent au minimum de pouvoir être analysés (sans être modifié). Et la plupart sont des logiciels qui sont totalement modifiables. La transparence est totale. Le problème majoritaire est que ce sont souvent des logiciels développés par des entreprises beaucoup moins influentes que les GAFAM et qui n’ont pas les avantages de posséder des bases de données gigantesques. Beaucoup de ces assistants libres utilisent les API de reconnaissance vocale des grands groupes (comme Google Speech API ou Bing Speech API). |
| La confidentialité (Exploitation des données, l’écoute, l’anonymat, sécurité des données, etc.) | La confidentialité de ces assistants vocaux est dite privées, que les données récupérées sont sécurisées et protégées, qu’elles ne servent qu’à l’amélioration du logiciel. De plus, les assistants vocaux ne sont pas censés écouter en ligne jusqu’à la détection du mot clé. Cependant, différents scandales ont éclaté accusant les entreprises d’avoir écouté des utilisateurs à leur insu. | La confidentialité de ces assistants dépend beaucoup des programmes utilisés. Beaucoup de ces assistants vocaux sont l’assemblage de plusieurs programmes (STT, TTS, Database) qui selon leur provenance assure une confidentialité des données ou non. Si le programme de reconnaissance vocale est l’API de Google, les données seront récupérées par Google. Beaucoup de programme peuvent fonctionner off-line ce qui présentent un certain avantage mais l’inconvénient d’être bien moins efficace, précis et peu évolutif. |
| L’accessibilité tarifaire (les assistants sont en tant que tel gratuits mais nécessitent d’avoir des appareils pouvant les exploiter qui eux ont un coût) | Les assistants sont gratuits cependant ils nécessitent l’achat d’une enceinte pour pouvoir leur parler de plus, le nombre d’appareils fonctionnant avec est limité par les protocoles imposés par les entreprises. Ce qui renforce le coût car pour un usage en domestique, l’achat est guidé par la compatibilité. | Les assistants sont gratuits cependant ils nécessitent l’achat d’un appareil pour l’implémenter, beaucoup de ces assistants sont légers et peuvent s’implémenter dans un Raspberry Pi. Pour un usage domestique, il est beaucoup plus simple d’utiliser les composants comme on veut. Que ça soit des produits déjà en vente sur les marchés ou que ça soit de créer ses propres appareils connectés avec capteurs etc. |
| La facilité d’utilisation (Est-ce que l’assistant est simple à mettre en place, est ce que le compléter par des appareils connectés est simple (kit déjà tout prêt ?) | C’est surement l’avantage premier de ce genre de logiciel non libre, c’est la facilité d’utilisation et de mise en place. Tout est guidé, ces assistants vocaux sont parfaits pour des personnes non-férus d’informatique et d’électronique. | Ces logiciels sont souvent plus durs à mettre en place. Il est nécessaire d’avoir quelques connaissances de base en informatique, électronique/domotique. Les assistants libres les plus célèbres sont relativement simple (ex : MyCroft) mais d’autres comme OpenJarvis sont beaucoup moins accessible au grand public. |
| Modifiable et modulable (Peuvent-ils être modifiés, modulés, personnalisés ?) | Ces logiciels sont difficilement voire carrément impossibles à modifier et à personnaliser. Les entreprises ont quand même changé un peu leur politique en dévoilant des API que les développeurs exploitent pour créer leurs propres modules. Cependant, ces modules sont limités par l’API fournie et donc dépendante de la volonté de l’entreprise. | Ces logiciels sont totalement modulable grâce à la transparence dont fait par les créateurs. De plus, cette liberté permet de moduler l’utilisation quasi à volonté. |
| Protocole d’utilisation (WiFi) | Ces assistants vocaux nécessitent une connexion internet pour fonctionner (mis à part la détection de mots clés. | Ces assistants vocaux fonctionnent pour la plupart à l’aide de connexion internet, mais cela n’est pas systématique. (Rappel : certains programmes de reconnaissance vocale ou autre peut fonctionner off-line). De plus, les capteurs et appareils connectés peuvent utiliser d’autres protocoles de communication (bluetooth, Z-wave, EnOcean). |
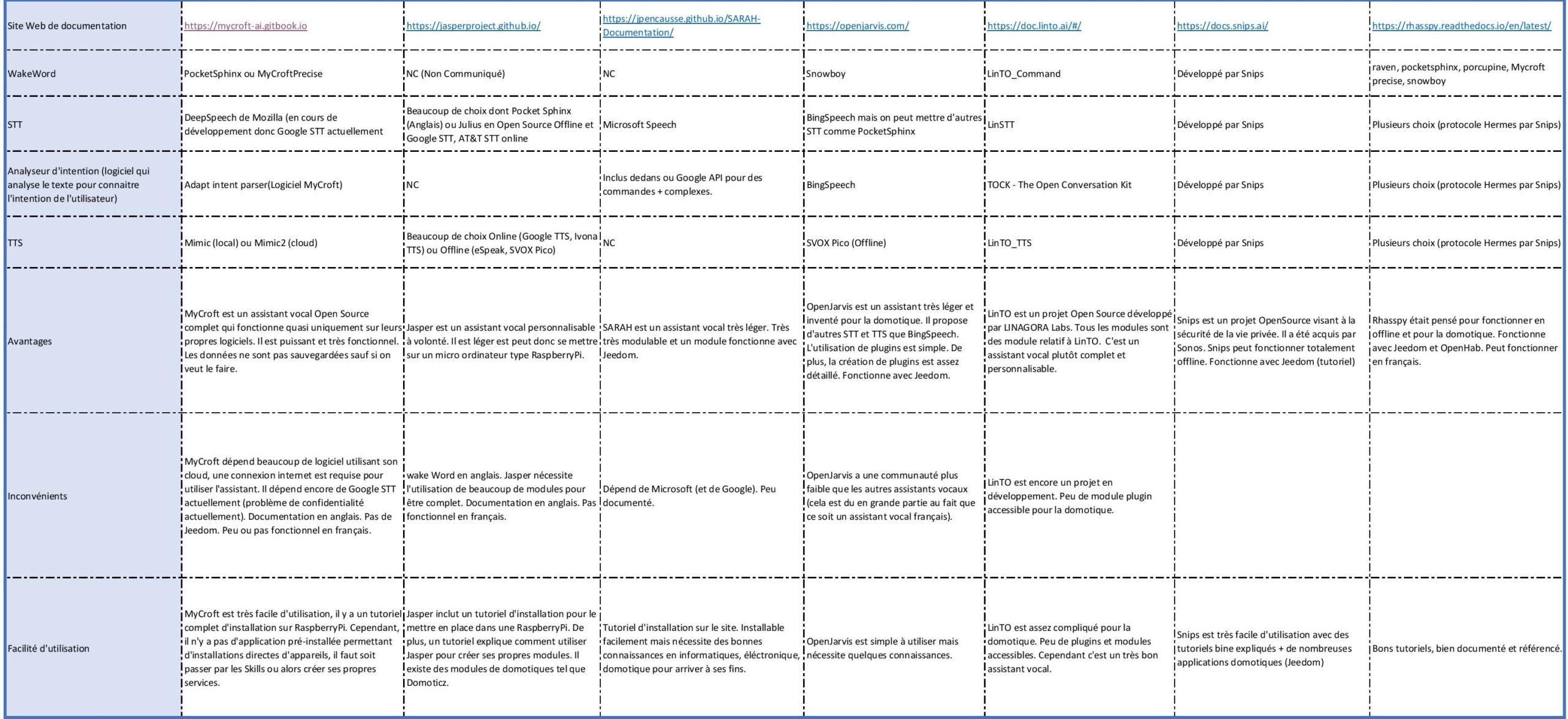
Comparatif entre les assistants vocaux Open Source (Cliquez sur l’image pour la voir en grand)
Comparatif de différents assistants vocaux Open Source (MyCroft, Jasper, S.A.R.A.H, OpenJarvis, Linto, Rhasspy). Pour voir l’image, cliquez dessus.
Nous avons choisi de travailler sur Rhasspy dans un premier temps car il s’agissait de l’assistant vocal le mieux documenté, le plus accessible avec beaucoup de possibilités de personnalisation, et un plugin pour Jeedom.
1. Matériel
Le matériel nécessaire est le suivant :
- Une RaspberryPi (RaspberryPi 4 dans notre cas)
- Une carte SD (Minimum 16GB)
- Un microphone USB (Plug and Play) (ou un autre type de microphone mais pas de configuration détaillée ici)
- Un Haut Parleur (Ici, prise Jack 3.5mm)
2. Installation de RaspberryPi OS Lite
Pour installer l’assistant vocal Rhasspy, il faut déjà installer une image adaptée sur la RaspberryPi . (Dans notre cas, nous installons l’image RaspberryPi OS Lite (32-Bits). On peut préparer la carte SD sous n’importe quel OS, voici la procédure à suivre sous Windows, ou sous Linux :
Sous Windows :
Installation de l’image
Dans un premier temps, il faut installer RaspberryPi Imager ici :
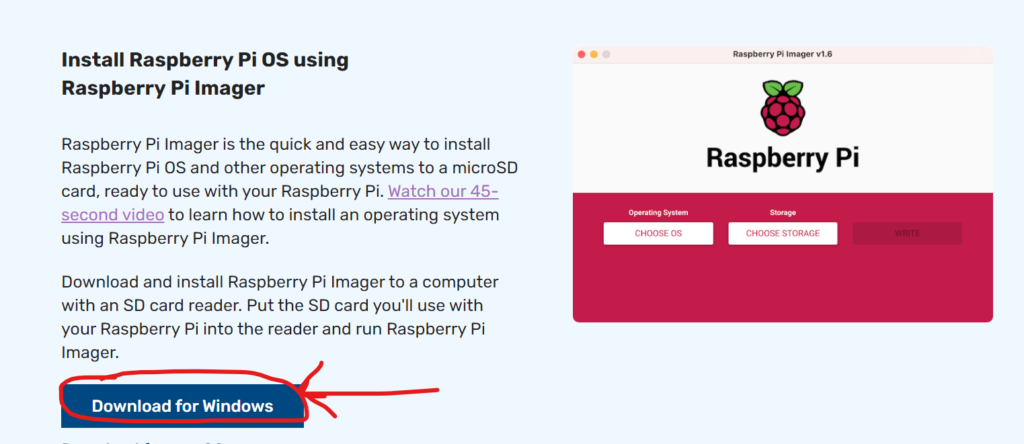
Ensuite, on l’installe puis on exécute le logiciel.
On doit arriver sur cette interface :

Cliquez sur Choisissez l’OS puis sur Raspberry Pi OS (Other) puis sur Raspberry PI OS Lite (32-Bits).
Maintenant insérez votre carte SD puis cliquez sur Choisissez le stockage et cliquez sur votre Carte SD
Enfin cliquez sur Ecrire
Puis patientez jusqu’à la fin de l’installation.
Sous Linux (Ubuntu x86)
Télécharger Raspberry Pi Imager dans le terminal :
wget https://downloads.raspberrypi.org/imager/imager_latest_amd64.deb
dpkg -i imager_latest_amd64.deb
Autorisation de la commande par SSH et activation du Wifi
Une fois l’installation terminée, rendez vous dans votre Gestionnaire de fichier, puis allez dans le volume de votre carte SD nommée boot (dans notre cas boot (E:) )
-> Créer un nouveau fichier -> Document Texte -> nommez le ssh et supprimer .txt (enlevez l’extension).
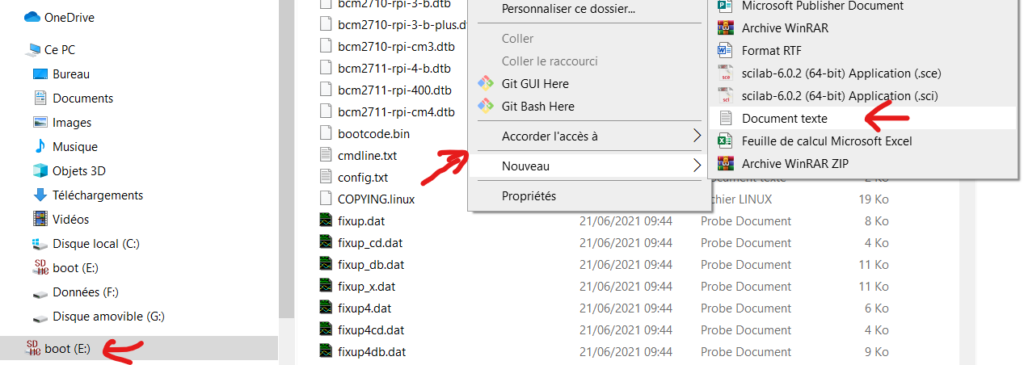
Vous devriez avoir un fichier comme ceci :

Vous avez maintenant autoriser l’activation du SSH au démarrage de la RaspberryPi.
Maintenant, on va permettre à la RaspberryPi de se connecter à internet (à la Wifi) au démarrage :
De la même manière, créez un nouveau fichier dans le volume boot que vous nommez cette fois ci wpa_supplicant.conf (enlevez l’extension .txt).
Ouvrez le avec un éditeur de texte et copiez ce texte :
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdevupdate_config=1country=<Insert 2 letter ISO 3166-1 country code here>network={ssid="<Name of your wireless LAN>"psk="<Password for your wireless LAN>"}
En remplaçant par vos valeurs :
Exemple : ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdevupdate_config=1country=FRnetwork={ssid="NomDeMaBoxInternet"psk="MotDePasseDeMaBoxInternet"}
Enrgistrez le fichier, retirez la carte SD, insérez la dans votre RaspberryPi et allumez la.
Voilà, vous avez installé l’image RaspberryPi OS Lite (32-Bits) en autorisant la connexion SSH et en actiavant la Wifi.
Vous n’avez plus qu’à la contrôler par SSH (ou via un Moniteur HDMI + un clavier).
Pour le SSH, vous avez besoin de l’adresse IP de la carte Raspberry PI. Il y a plusieurs solutions, soit vous accéder à l’interface de votre routeur (souvent 192.168.1.1 ou 192.168.0.1 dans votre barre de recherche URL de votre navigateur Web) et cherchez dans les appareils connectés la carte Raspberry Pi et vous récupérez son adresse IP (du plus souvent du type 192.168.1.XX). Soit vous scannez les appareils connectés grâce à des scanners IP (Ex : Advanced IP Scanner). Soit vous avait un moniteur HDMI, et au démarrage de la raspberryPi, lorsque l’écran de connexion apparaît, remonter dans les lignes jusqu’à voir apparaitre « My IP adress is … »
Une fois l’adresse IP connue, vous n’avez plus qu’a vous connecter en SSH avec la commande :
ssh pi@<adresseIPRaspberryPI>(Ex : ssh pi@192.168.1.13)
3. Installation de Rhasspy
Vous pouvez retrouver la documentation officielle de Rhasspy ici (détaillée, mais en anglais).
Nous allons maintenant procéder à l’installation de Rhasspy sur la RaspberryPi fraîchement configurée.
A partir du terminal de commande, rentrez la commande suivante :
$ curl -sSL https://get.docker.com | sh
Une fois que Docker est installé, on rajoute l’utilisateur Pi au groupe Docker comme ceci :
$ sudo usermod -aG docker pi
Puis on redémarre la RaspberryPi :
$ sudo reboot
Une fois, la Raspberry Pi redémarrée, on lance la commande :
$ docker pull rhasspy/rhasspy
Une fois que l’image Rhasspy est téléchargée et extraite, on va procéder à son installation avec la longue commande ci-dessous :
$ docker run -d \-p 12101:12101 \--name rhasspy \--restart unless-stopped \-v "$HOME/.config/rhasspy/profiles:/profiles" \-v "/etc/localtime:/etc/localtime:ro" \--device /dev/snd:/dev/snd \rhasspy/rhasspy \--user-profiles /profiles \--profile fr
Voilà, vous venez d’installer Rhasspy ! Vous pouvez maintenant accéder à l’interface Web permettant de configurer Rhasspy graphiquement.
Pour accèder à cette interface Web, il suffit de taper dans votre barre de recherche :
http://<VotreAdresseIpdeRaspberryPi>:12101 (Ex : Dans mon cas : http://192.168.1.13:12101)
Vous devriez arriver sur une interface comme ceci :
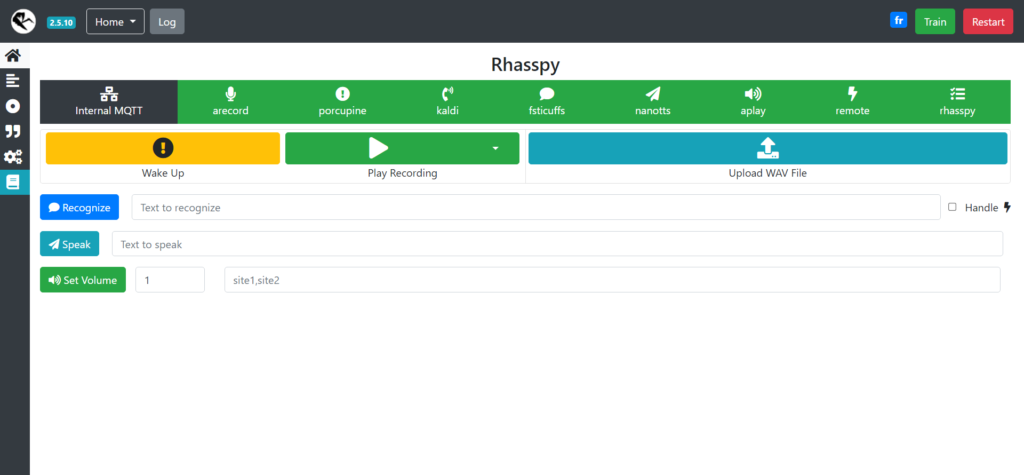
4. Configuration de Rhasspy
On peut maintenant configurer l’assistant Vocal Rhasspy en allant dans Settings. Puis pour chaque paramètre vous pouvez configurer comme ceci :
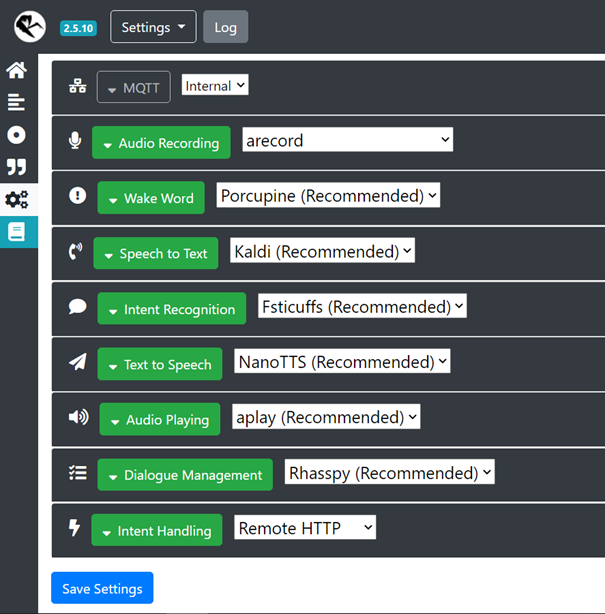
Pour le paramètre Audio Recording, j’ai choisi de passer par le programme de base de linux (arecord) et pour le configurer j’ai choisi Default Audio Device.
Vous pouvez voir ce que vous avez comme entrées audio de disponibles en cliquant sur Refresh. Le bouton Test permet de voir quelles entrées audio sont fonctionnelles en indiquant Working! à leur côté.

(Si vous voulez savoir sur quoi est branché votre micro, dans un temrinal de commande tapez la commande
arecord -l
Et cherchez votre micro. (Dans mon cas, le Microphone est branché sur la carte 1 et c’est le device 0) )

Pour le paramètre Wake Word, vous pouvez choisir votre mot-clé (dans mon cas, j’ai choisi « Jarvis »)
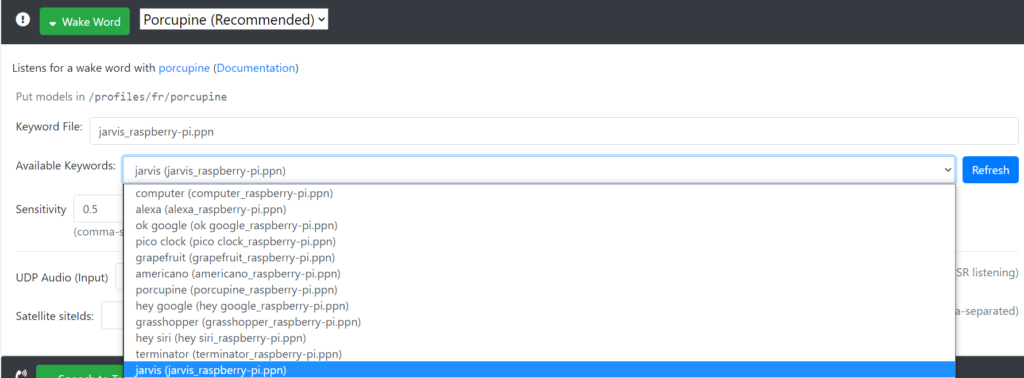
Pour les autres paramètres, mettez les configurations recommandés, puis pour Intent Handling mettez Remote HTTP.
Ensuite sauvegardez, vous allez devoir redémarrer le Rhasspy et téléchargez des données. Laissez vous guider.
Testez votre Rhasspy en allant à la page d’accueil.
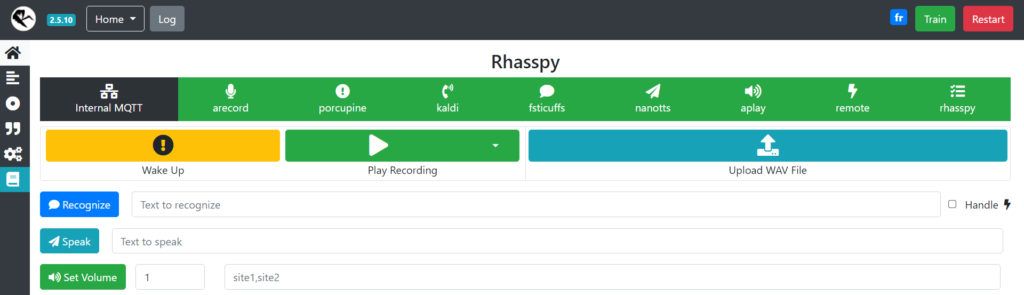
On teste d’abord le STT :
- Par exemple, cliquez sur « Wake Up », puis dites « Quelle heure est-il ? » Vous devriez voir ça ——————————>
Puis on teste le Wake Word :

- Dites maintenant votre mot-clé de réveil (dans mon cas « Jarvis »), puis dites « Quelle est la température ». Vous devriez voir ça.
Et en dernier, testez le TTS :
Dans la barre à côte de « Speak« , tapez un texte que vous voulez que Rhasspy lise puis cliquez sur Speak.
Si votre Rhasspy parle alors tout fonctionne.
Voilà, vous avez un assistant vocal fonctionnel.
Votre assistant ne comprend qu’un nombre limité de phrases (vous pouvez les voir dans l’onglet « Sentences »).
Nous verrons dans le chapitre 7. Usages comment augmenter la capacité de compréhension de Rhasspy et comment l’utiliser avec Jeedom.
5. Installation et Configuration de Jeedom
Deux cas de figures s’offrent à vous. Soit vous avez déjà installé un serveur Jeedom et dans ce cas là vous pouvez directement vous rendre au chapitre Liaison et Connexion entre Rhasspy et Jeedom. Soit vous n’avez pas encore installé Jeedom et dans ce cas, vous pouvez continuer à lire la suite.
Vous pouvez retrouver toute la documentation officielle de Jeedom ici. Mais on va résumer l’installation et la configuration ci-dessous :
Installation de Jeedom sur la Raspberry Pi contenant Rhasspy :
Rendez vous sur un terminal de commande de votre Raspberry Pi (comme avant, par SSH ou via un écran et un clavier) puis rentrez cette commande :
wget -O- https://raw.githubusercontent.com/jeedom/core/master/install/install.sh | sudo bash
L’installation prend plusieurs dizaines de minutes.
Une fois l’installation terminée, redémarrez votre carte :
sudo reboot
Voilà, votre serveur Jeedom est fonctionnel.
Configuration de Jeedom
Création d’un compte Jeedom
Si vous n’avez pas un compte Jeedom, il faut vous en créer un ici et puis remplir les champs demandés
Configuration
Pour configurer votre Jeedom, il faut connaître l’adresse IP du serveur qui gère Jeedom. Il peut soit s’agir de votre installation Jeedom déjà faite au préalable, ou alors de la carte Raspberry Pi sur laquelle on vient d’installer Rhasspy et Jeedom. Dans ce cas là, vous connaissez déjà l’adresse IP (Voir procédure du début).
Pour accèder à l’interface Jeedom et pouvoir configurer votre serveur Jeedom, il suffit de taper dans la barre de recherche de votre navigateur web :
http://<AdresseIPduServeurJeedom> (Ex : Dans mon cas, ma Raspberry Pi contient l’assistant vocal Rhasspy et le serveur Jeedom, c’est donc la même adresse IP. Je me connecte à http://192.168.1.13)
Vous devriez arriver à un écran de connexion comme ceci :

Connectez vous en utilisant le nom d’utilisateur et mot de passe par défauts qui sont « admin ».
Lier votre Jeedom à votre compte Market.
- Une fois connecté à votre Jeedom, vous devez aller sur Réglages → Système → Configuration
- Cliquez sur l’onglet Mises à jour
- En dessous, cliquez sur l’onglet Market
- Cochez la case activer
- Remplissez l’adresse :
https://market.jeedom.com - Renseignez également les champs Nom d’utilisateur et Mot de passe en fonction de vos identifants (identifiants du Market et non pas de Jeedom)
- Vous pouvez tester pour vérifier que la connexion s’effectue correctement.
- N’oubliez pas de sauvegarder !
Changer le mot de passe par défaut de Jeedom
Une des étapes importantes est de changer le mot de passe par défaut de votre compte Jeedom, pour cela cliquez sur Réglages → Système → Utilisateurs :
Une fois dessus, vous avez juste à choisir la ligne avec l’utilisateur admin et à cliquer sur Mot de passe :

Une fenêtre va vous demander le mot de passe. Attention à bien le retenir, ou vous ne pourrez plus accéder à votre Jeedom.
Voilà, votre Jeedom est configuré. Vous pouvez en apprendre plus sur Jeedom, et les fonctionnalités de base en cliquant ici.
6. Liaison entre Rhasspy et Jeedom
Si on fait un état des lieux, on a d’un côté un assistant vocal qui sait écouter, qui comprend ce qu’on lui dit et qui le traduit en « event » mais qui ne fait rien. De l’autre côté, on a un serveur de domotique qui ne comprend pas et qui n’écoute pas mais qui sait agir avec des « events ».
Si on veut avoir une maison intelligente que l’on peut contrôler vocalement, il nous suffit de lier notre assistant vocal à Jeedom pour obtenir une interaction vocale entre nos équipements connectés et notre voix.
Nous allons voir dans ce chapitre, comment lier Rhasspy et Jeedom pour avoir un assistant vocal fonctionnel appliquée à la domotique.
Installation du plugin Rhasspy pour Jeedom
Jeedom est un outil très puissant grâce à son grand nombre de plugins disponibles (officiels ou non-officiels), ce qui le rend très modulable et très personnalisable.
Ici, nous allons utiliser un plugin qui se nomme jeeRhasspy et qui permet de lier et d’utiliser Rhasspy sous jeedom. Vous pouvez retrouver toute la documentation officielle ici
Dans un premier temps, on procède à l’installation :
Sur la page de Jeedom, dans la barre d’outil du haut, rendez vous dans Plugin -> Gestion des plugins.
Ensuite, allez dans Market et Cherchez le plugin jeeRhasspy.
Cliquez sur Installez stable et lorsque le téléchargement est terminé, vous devriez voir apparaitre cet onglet :

Cliquez sur Ok.
Vous êtes maintenant sur la page de configuration du plugin jeeRhasspy.
Configuration du plugin jeeRhasspy
En arrivant sur la page de configuration du plugin jeeRhasspy, vous devriez voir apparaitre cette fenêtre :
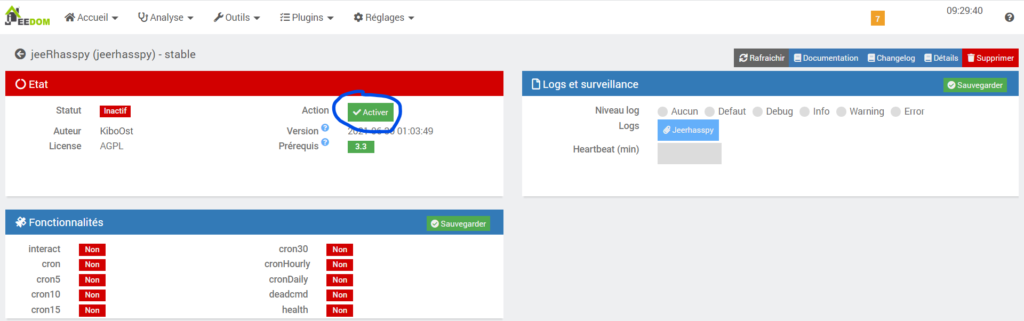
La première chose à faire est de cliquez sur Activer dans la barre Etat.
On voit apparaitre alors une nouvelle barre Configuration et la barre Etat qui est passé au vert:
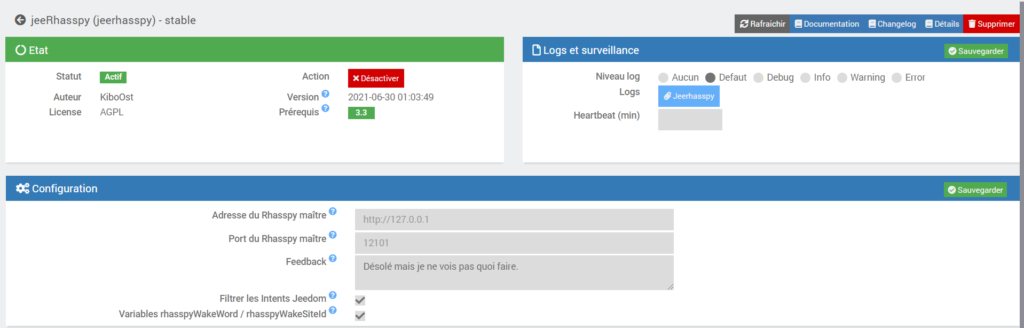
On s’intéresse maintenant à la barre Configuration.
On retrouve 5 paramètres :
- Adresse du Rhasspy maître : On renseigne ici l’adresse IP de notre Raspberry Pi contenant l’assistant vocal Rhasspy (dans mon cas : http://192.168.1.13)
- Port du Rhasspy maître : On renseigne ici le port de notre Raspberry Pi contenant l’assistant vocal Rhasspy (dans le cas général si vous avez bien suivi la procédure : 12101)
- Feedback : C’est la réponse (que va lire votre Rhasspy) si Jeedom ne trouve pas de correspondance à ce que lui demande le Rhasspy.
- Filtrer les Intents Jeedom : Les Intents sont les mots clés que Rhasspy envoie à Jeedom pour lui traduire la demande de l’utilisateur. (Ex : On demande à Rhasspy « Quelle heure est-il ? », Rhasspy va envoyer le mot-clé [GetTime] à Jeedom). Filtrer les Intents Jeedom revient à ce que le plugin jeeRhasspy ne laisse passer à Jeedom que les Intents de Rhasspy terminant par le mot Jeedom. (Ce paramètre est pratique lorsque Rhasspy ne sert pas qu’à communiquer avec Jeedom. Dans notre cas on peut décocher la case pour simplifier les Intents à envoyer de Rhasspy à Jeedom (plutôt [GetTime] que [GetTimeJeedom])).
- Variables rhasspyWakeWord / rhasspyWakeSiteId : Quand le wakeword est détecté, le plugin renseigne ces deux variables avec le wakewordId et siteId. Vous pouvez alors déclencher un scénario sur
#variable(rhasspyWakeWord)#pour par exemple couper la musique le temps de votre demande.
Remplissez tous les champs puis cliquez sur sauvegarder. La configuration donne ça :
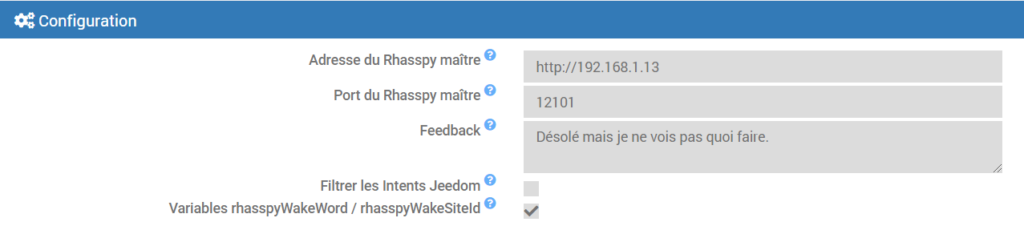
Maintenant, dans la barre d’outil Jeedom, allez dans Plugin -> Communication -> jeeRhasspy.
On arrive sur cette page :
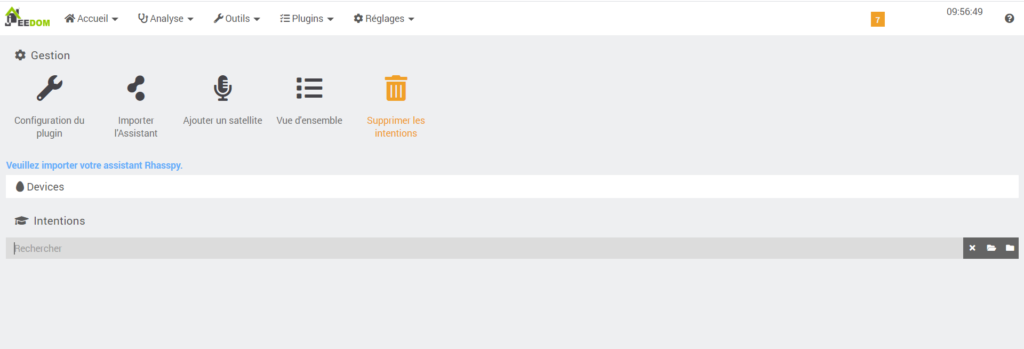
Cliquez sur Importer l’Assistant.
A l’importation, il y a trois options possible: Lors de la première importation, ces options n’ont pas d’incidence.
- Conserver toutes les Intentions : Ne supprime aucun Intent, et crée ceux non présent dans Jeedom.
- Supprimer les Intentions qui ne sont plus dans l’assistant : Supprime seulement les Intents de Jeedom qui ne sont plus dans Rhasspy.
- Supprimer et recréer toutes les Intentions : Supprime tous les Intents de Jeedom, avant de recréer les Intents présents sur Rhasspy.
L’importation de l’assistant va créer :
- Un Device : C’est votre machine Rhasspy.
- Vos Intentions : Chaque Intent présent sur votre assistant Rhasspy.
Dans l’onglet Devices, vous devriez voir apparaître trois boutons sous son icône :
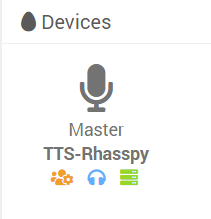
- Configurer le profile Rhasspy : Permet de configurer automatiquement le profile Rhasspy du device. Voir ci-dessous.
- Test TTS sur ce device : Effectue un test TTS que vous entendrez sur le device sur lequel vous avez cliqué.
- Ouvrir l’interface de ce device : Ouvre l’interface Rhasspy du device dans un autre onglet.
Vous pouvez alors tester si votre liaison Jeedom -> Rhasspy est fonctionnel en cliquant sur le casque Bleu qui va envoyer le texte « Default, ceci est un test » au Rhasspy qui va vous le lire. Si vous entendez bien votre Rhasspy le lire alors la liaison est fonctionnelle.
Maintenant cliquez sur le bouton orange de Configuration. 2 Options apparaissent :
- Utiliser l’URL interne (à faire si votre Rhasspy et votre serveur Jeedom fonctionne sur le même réseau)
- Utiliser l’URL Externe (à faire si votre Rhasspy et votre serveur Jeedom fonctionne sur des réseaux différents)
Laissez la case Configurer l’event Wakeword Detected cochée puis cliquez sur Ok.
Maintenant, on va tester la liaison Rhasspy -> Jeedom pour vérifier que Rhasspy envoie bien les informations à Jeedom. Pour ce faire, demander juste à Rhasspy l’heure en lui disant : « Jarvis, quelle heure est-il? »
Si la liaison est fonctionnelle, alors Rhasspy devrez vous répondre « Désolé mais je ne vois pas quoi faire ».
Si non, vérifiez bien sur votre interface Rhasspy (http://<AdresseIP_Rhasspy>:12101) que Rhasspy a détecté ce que vous avez dit.
Si Rhasspy détecte bien votre voix mais qu’il ne répond pas, c’est que la liaison Rhasspy -> Jeedom ne marche pas. Dans ce cas, sur la page d’Accueil de Rhasspy cochez la case « Handle » et ré-essayez.
Vous pouvez également vérifier dans les Settings -> Intent Handling que la clé API est bien la même que dans les paramètres de Jeedom ->API.
Maintenant que votre liaison est fonctionnelle, il est temps de rendre le service utile et de permettre à Jeedom de savoir quoi faire de ces Intents envoyés par Rhasspy.
7. Usages
On a maintenant un assistant vocal fonctionnel, un serveur de domotique fonctionnel et une liaison entre les deux fonctionnelle. Il ne manque plus qu’à utiliser ce nouveau service.
Pour se faire, il faut comprendre comment marche les Intents.
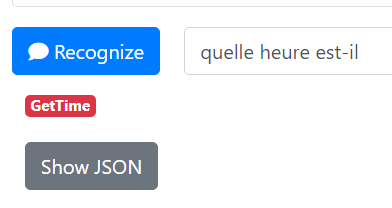
Lorsque l’on appelle Rhasspy et qu’on lui fait une demande comme par exemple « Quelle heure est-il ? ». Rhasspy va traduire cette demande vocale en texte, puis il va analyser ce texte pour comprendre quelles sont les intentions de l’utilisateur qui sont dans ce cas Obtenir L’heure. Il va donc traduire cette intention en ce qu’on appelle un event JSON, c’est l’Intent, puis va envoyer cette traduction à Jeedom qui va analyser l’Intent et agira en fonction de la nature de ce dernier. Dans notre cas, il va recevoir un Intent qui sera de nature « Obtenir L’heure » et donc Jeedom va aller chercher l’heure, et envoyer un texte à Rhasspy du type « Il est #heure# heures #minute# » (avec #heure# la variable de de l’heure et #minute# la variable de la minute).
Les Intents JSON sont au format :
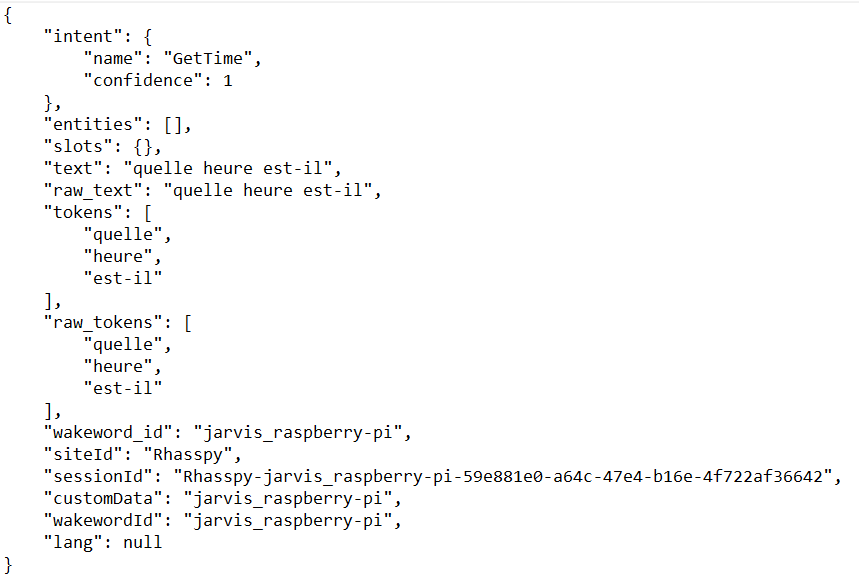
Création d’une commande vocale complète
On va donc voir ici comment créer une commande vocale complète, celle de demander l’heure.
Dans un premier temps, il faut régler Rhasspy de sorte à ce qu’il comprenne ce qu’on lui dit. (Rhasspy étant un assistant offline, il faut l’entrainer à reconnaitre les commandes).
Sur l’interface de Rhasspy, allez dans l’onglet Sentences. Vous devriez voir un bloc de texte déjà pré-remplis. Il se trouve que la commande vocale pour obtenir l’heure est déjà configurée.

On peut décomposer la commande en deux ->
[GetTime] est le nom de l’Intent
« quelle heure est-il », »il est quelle heure » sont les phrases que vous devez prononcez pour que Rhasspy en déduise que vous voulez l’heure. Une fois ces phrases prononcées, Rhasspy va envoyer la commande [GetTime] à Jeedom (plus quelques autres détails que nous ne spécifierons pas, mais que vous pouvez retrouver sur la documentation officielle en anglais ici)
Maintenant nous allons créer l’action à effectuer lorsque Jeedom reçoit cet Intent.
Allez dans Jeedom (http://<AdresseIPdeJeedom>) -> Outils -> Scénario.
Cliquez sur Ajouter et nommez le scénario (par exemple « ObtenirLHeure ») puis cliquez sur Ok. Vous arrivez sur cette page :
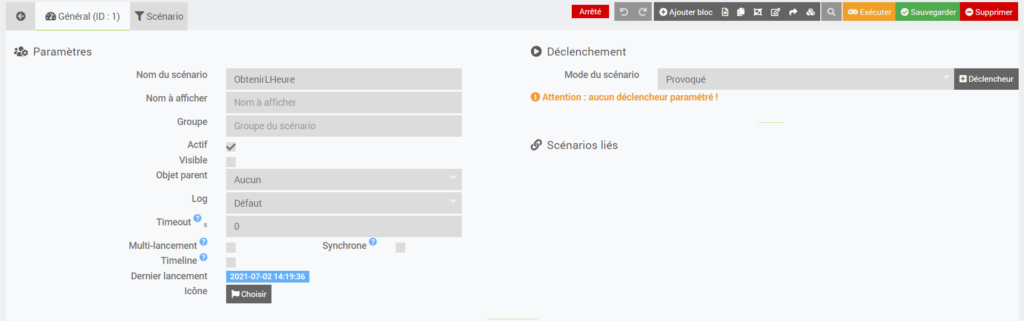
Vous pouvez attribuer un groupe au scénario (cela permet de classifier lorsque vous en avez beaucoup).
Allez dans l’onglet scénario (en haut à gauche).
Vous arrivez ici :

Cliquez sur Ajouter bloc -> Action -> Ajouter .
Dans le Bloc Action, cliquez sur Ajouter -> Action.
Cliquez ensuite sur le bouton à droite de la barre de texte :

Sélectionnez TTS-Rhasspy (TTS-Default) dans Equipement et sélectionnez dynamicSpeak dans Commande Action.

Vous obtenez ça.
Dans la barre de texte message qui est apparu à droite, écrivez :
Il est #hour# heures #minute#
Maintenant, cliquez sur Sauvegardez.
Voilà, l’action à effectuer est prête. Il ne reste plus qu’a lier l’Intent à l’action.
Pour cela, allez dans Plugin -> Communication -> jeeRhasspy (n’oubliez pas d’importer l’assistant à chaque fois que vous ajouter des commandes dans Rhasspy).
Allez dans l’onglet Intentions et cliquez sur l’Intent [GetTime]
Dans scénario, sélectionnez le scénario ObtenirLHeure que l’on vient de créer puis dans Action, sélectionnez Start et enfin sauvegardez.
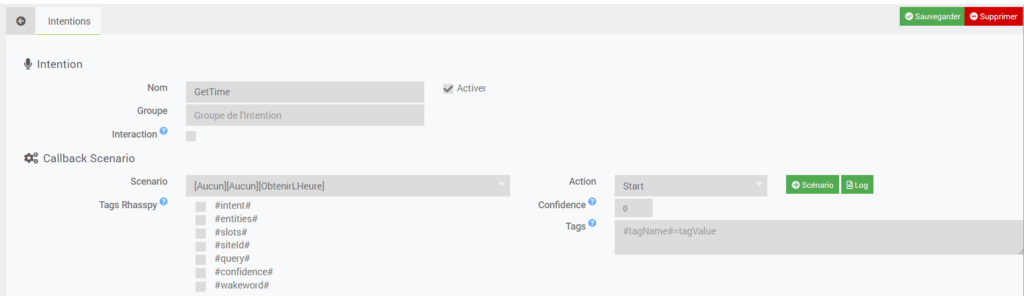
Et voilà, c’est fini !!
Vous n’avez plus qu’à tester votre commande à l’oral en disant « Jarvis, quelle heure est-il ? »
Si il répond vous avez réussi, si non vérifiez que vous avez bien suivi toutes les étapes.
Vous avez maintenant les outils de base pour créer des commandes vocales.
Si vous voulez aller plus loin, consulter les documentations officielles plus complètes :Rhasspy -> https://rhasspy.readthedocs.io/en/latest/
Jeedom -> https://doc.jeedom.com/fr_FR/
Plugin jeeRhasspy -> https://kiboost.github.io/jeedom_docs/plugins/jeerhasspy/fr_FR/


[…] votre installation existante. Pour des solutions plus avancées, explorez des options comme Rhasspy avec Jeedom, un assistant vocal open source pour la […]