
Monitoring d’une serre, du capteur jusqu’au serveur via le trio Lora, InfluxDB, Grafana
23 juillet 2019Bonjour à tous,
Je m’appelle Sylvain et Aujourd’hui je vous présente le résultat mon sujet de stage.
Vous avez toujours souhaité installer un capteur chez vous ?
Par exemple un capteur de température ET d’humidité chez vous, dans votre jardin, au-dessus de votre aquarium ou même dans votre serre, voir une serre aquaponique ?
Pour ma part, il s’agit de la dernière proposition :

PARTIE 0: CHOIX DU MATÉRIEL
I. LE CAPTEUR
Pour commencer, on doit choisir un capteur qui permet de réaliser ces fonctions. C’est pour cela que j’ai décidé de choisir le DHT22
Qu’est ce qu’un DHT22 ?


C’est un capteur d’humidité et de température, il permet de recueillir les deux données simultanément (température/humidité), il possède également quelques caractéristiques intéressantes :
Il permet la mesure de températures pouvant varier de -40 à 125 degrés Celsius avec une précision de +/- 0.5 degrés Celsius
Il permet la mesure de l’humidité pouvant varier de 0% à 100% avec une précision variant de +/- 2% à 5%
Ce qui largement supérieur à sa précédente version, le capteur DHT11 ne pouvant varier que de 0 à 50 degrés Celsius avec une précision de 2 degrés Celsius et une tranche de mesure d’humidité variant de 20% à 80% avec une précision de +/- 5%
Mais le DHT22 à une fréquence d’échantillonnage de 0.5Hz, ce qui correspond à une mesure toutes les 2 secondes à la différence de son prédécesseur qui lui avait 1 Hz de fréquence d’échantillonnage ce qui permet d’avoir une mesure toutes les secondes
Le DHT22 est également un peu plus grand que son petit frère en affichant des dimensions de 15.1mm x 25mm x 7.7mm alors que ce dernier ne faisait que 15.5mm x 12mm x 5.5mm.
Étant donné que nous n’avons pas besoin d’une tel rapidité et que l’écart de dimension est minime et permet tout de même de se faire discret dans son utilisation de tous les jours, le DHT11 ne possédait aucun argument permettant de le choisir en comparaison du DHT22.
D’autant plus que les 2 capteurs ont les mêmes besoins en courant/tension.
II. LE MICROCONTROLEUR
Quel Nano Ordinateur choisir alors ?
Pour ma part, je vais opter pour un Pycom Lopy4

qui vient se greffer sur une extension board, un Pycom makr pour la programmation

Ce qui nous donne une fois mis ensemble (attention au sens je vous conseille de bien regarder les signes distinctifs des deux parties pour pouvoir l’assembler dans le bon sens sinon toute la suite ne pourra pas fonctionner)

Une Pycom Lopy, c’est un Nano Ordinateur très peu gourmand en énergie, pour maintenir LoRa actif (nous reviendrons par la suite sur ce qu’est LoRa) il nous faudra uniquement 3 mA, sous une alimentation variant de 3,3 à 5,5 Vcc . Cela permet d’obtenir une consommation énergétique très faible.
Le Pycom Lopy est également très facile de prise en main. En effet de nombreux documents techniques sont facilement disponibles sans devoir chercher des heures et des heures pour en obtenir un qui nous permettra d’avoir l’information voulu !
Il est en plus, doté de 8 MB de mémoire flash ainsi que de 4 MB de mémoire RAM, de dimensions réduites qui mettront tout le monde d’accord : 55mm x 20mm x 3,5mm, un poids de 7 grammes, un module Bluetooth standard ainsi qu’un module wifi 802.11 permettant une connexion SSH par exemple et évidemment le plus important pour nous permettre de récupérer les données dans notre situation, un module LoRa compatible LoRaWan basé sur un SX1272.
PARTIE 1 : PROTOCOLE LORA
LoRa nous sera fortement utile car en effet LoRaWAN est un protocole de télécommunication permettant une communication à bas débit pour des objets à faible consommation électrique communiquant selon la technologie LoRa et connectés à Internet grâce à de multiples passerelles, dans notre situation.
Il permettra de faire le lien entre le capteur/Microcontrôleur et un serveur tampon que nous reparlerons un peu plus tard.
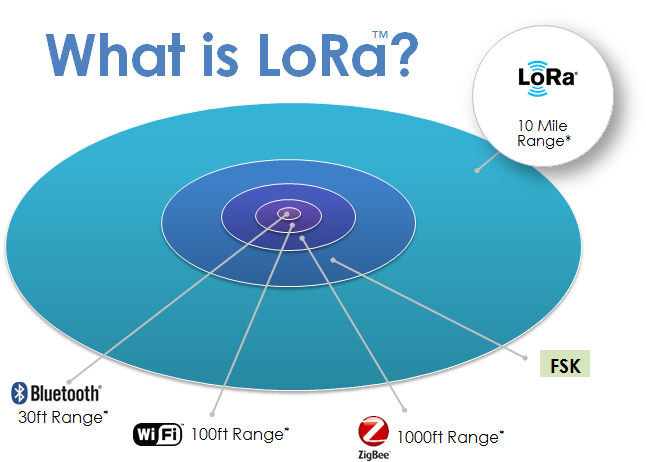
Un SX1272 est un émetteur-récepteur qui est doté du modem LoRa à longue portée qui permet d’offrir des communications à spectre étalé ultra-longue portée ainsi qu’une très bonne immunité aux interférences tout en réduisant la consommation d’énergie, que demander de plus !
PARTIE 2: CABLAGE
Pour permettre l’exploitation des données du capteur DHT22, il est nécessaire de brancher le capteur sur notre Pycom Lopy ce qui nous permettra de lire les données sortant de celui ci.
Pour le branchement rien de plus facile. Reproduisez le schéma suivant :

Pour vous connectez à votre Pycom Lopy, branchez les composants comme indiqué sur la photo suivante (petite astuce pour l’antenne LoRa et la brancher au bonne endroit, elle se situe entre l’alimentation et le Gnd). Mettez sous tension en branchant l’alimentation.

PARTIE 3: PREPARATION POUR LE CODAGE
Pour information, Les sources sont CC-BY-NC-SA https://creativecommons.org/licenses/by-nc-sa/3.0/fr/
Maintenant vous pouvez aller sur votre Ordinateur et connecter vous au wifi de votre Pycom (exemple : lopy-wlan-xxxx), le mot de passe par défaut est : www.pycom.io
Si vous avez réussi à vous connecter à la Lopy, on va pouvoir commencer à la programmer.
Pour cela, il vous faudra créer un fichier qui portera le nom : main.py
On le placera dans un dossier du nom de votre choix.
Vous pouvez récupérer les codes python dont nous allons parler dans le fichier zip suivant :
zip python
Le fichier main.py c’est le script qui s’exécute directement après le fichier boot.py et doit contenir le code principal que vous souhaitez exécuter sur votre appareil.
Le main.py lui contiendra ce code :
from network import LoRa
import socket
import binascii
import struct
import pycom
import time
from machine import Pin
from machine import enable_irq, disable_irq
#################### Define LoraWan ########################
# for EU868
LORA_FREQUENCY = 868100000
LORA_GW_DR = "SF7BW125" #DR_5
LORA_NODE_DR = 5
# initialize LoRa in LORAWAN mode.
# Please pick the region that matches where you are using the device:
# Asia = LoRa.AS923
# Australia = LoRa.AU915
# Europe = LoRa.EU868
# United States = LoRa.US915
lora = LoRa(mode=LoRa.LORAWAN, region=LoRa.EU868)
# create an OTA authentication params
dev_eui = binascii.unhexlify(your_dev_eui)
app_eui = binascii.unhexlify(your_app_eui)
app_key = binascii.unhexlify(your_app_key)
# set the 3 default channels to the same frequency (must be before sending the OTAA join request)
lora.add_channel(0, frequency=LORA_FREQUENCY, dr_min=0, dr_max=5)
lora.add_channel(1, frequency=LORA_FREQUENCY, dr_min=0, dr_max=5)
lora.add_channel(2, frequency=LORA_FREQUENCY, dr_min=0, dr_max=5)
# join a network using OTAA
lora.join(activation=LoRa.OTAA, auth=(dev_eui, app_eui, app_key), timeout=0,
dr=LORA_NODE_DR)
# wait until the module has joined the network
while not lora.has_joined():
time.sleep(5)
print('Not joined yet...')
print("Joined")
# remove all the non-default channels
for i in range(3, 16):
lora.remove_channel(i)
# create a LoRa socket
s = socket.socket(socket.AF_LORA, socket.SOCK_RAW)
# set the LoRaWAN data rate
s.setsockopt(socket.SOL_LORA, socket.SO_DR, LORA_NODE_DR)
# make the socket blocking
s.setblocking(True)
time.sleep(5.0)
#################### End of define LoraWan ###########
def getval(pin):
ms = [1]*700 # needs long sample size to grab all the bits from the DHT
time.sleep(1)
pin(0)
time.sleep_us(10000)
pin(1)
irqf = disable_irq()
for i in range(len(ms)):
ms[i] = pin() ## sample input and store value
enable_irq(irqf)
# for i in range(len(ms)): #print debug for checking raw data
# print (ms[i])
return ms
def decode(inp):
res= [0]*5
bits=[]
ix = 0
try:
#if inp[0] == 1 : ix = inp.index(0, ix) ## skip to first 0 # ignore first '1' as probably sample of start signal. *But* code seems to be missing the start signal, so jump this line to ensure response signal is identified in next two lines.
ix = inp.index(1,ix) ## skip first 0's to next 1 # ignore first '10' bits as probably the response signal.
ix = inp.index(0,ix) ## skip first 1's to next 0
while len(bits) < len(res)*8 : ##need 5 * 8 bits :
ix = inp.index(1,ix) ## index of next 1
ie = inp.index(0,ix) ## nr of 1's = ie-ix
# print ('ie-ix:',ie-ix)
bits.append(ie-ix)
ix = ie
except:
print('6: decode error')
print('length:')
print(len(inp), len(bits))
return([0xff,0xff,0xff,0xff])
# print('bits:', bits)
for i in range(len(res)):
for v in bits[i*8:(i+1)*8]: #process next 8 bit
res[i] = res[i]<<1 ##shift byte one place to left
if v > 5: # less than 5 '1's is a zero, more than 5 1's in the sequence is a one
res[i] = res[i]+1 ##and add 1 if lsb is 1
# print ('res', i, res[i])
if (res[0]+res[1]+res[2]+res[3])&0xff != res[4] : ##parity error!
print("Checksum Error")
print (res[0:4])
# res= [0xff,0xff,0xff,0xff]
#print ('res:', res[0:4])
return(res[0:4])
def DHT22(pin):
res = decode(getval(pin))
hum = res[0]*256+res[1]
temp = res[2]*256 + res[3]
if (temp > 0x7fff):
temp = 0x8000 - temp
return (temp, hum)
#################### End of define DHT22 ###########
#################### Main program #################
def go_DHT():
dht_pin=Pin('P9', Pin.OPEN_DRAIN) # connect DHT22 sensor data line to pin P9/G16 on the expansion board
dht_pin(1) # drive pin high to initiate data conversion on DHT sensor
while True:
temp, hum = DHT22(dht_pin)
temp = temp//10
hum = hum//10
pkt = str(temp).encode() # Encode the data
pkh = str(hum).encode() # Encode the data
testpkall = pkt+pkh # Concatenate the 2 data encoded
s.send(testpkall) # Send the data
time.sleep(300) # Break of 300sec before the next run of your program
pycom.heartbeat(False)
go_DHT()
#################### End of Main program #################
Il existe également un deuxième fichier qui peut se révéler être nécessaire, mais pas dans notre cas, mais nous allons tout de même le créer et le laisser vide,il s’agit du fichier “boot.py”
Le fichier boot.py c’est le premier script qui s’exécute sur votre module lorsqu’il s’allume. Il est souvent utilisé pour connecter un module à un réseau WiFi afin que Telnet et FTP puissent être utilisés sans se connecter au point d’accès WiFi créé par le module et ne pas encombrer le main.py file. Dans notre cas, vous n’avez pas besoin d’utiliser un boot.py pour ces raisons, on va le laisser vide et l’ajouter à notre dossier créé juste avant.
Avant de continuer sur ce code et le mettre en marche, on va créer un serveur tampon sur TheThingsNetwork de 7 jours qui nous permettra d’utiliser tous ces composants de manière efficace et permettre une bonne analyse.
PARTIE 4: LA RÉCUPÉRATION DE DONNÉES VIA TTN
The Things Network nous permettra de sauvegarder les données reçues assez rapidement et comme vous l’aurez donc compris, The Things Networks nous servira de serveur tampon où les données seront stockées pendant une durée de 7 jours ainsi que de site web pour visualiser les données rentrantes en temps réels.
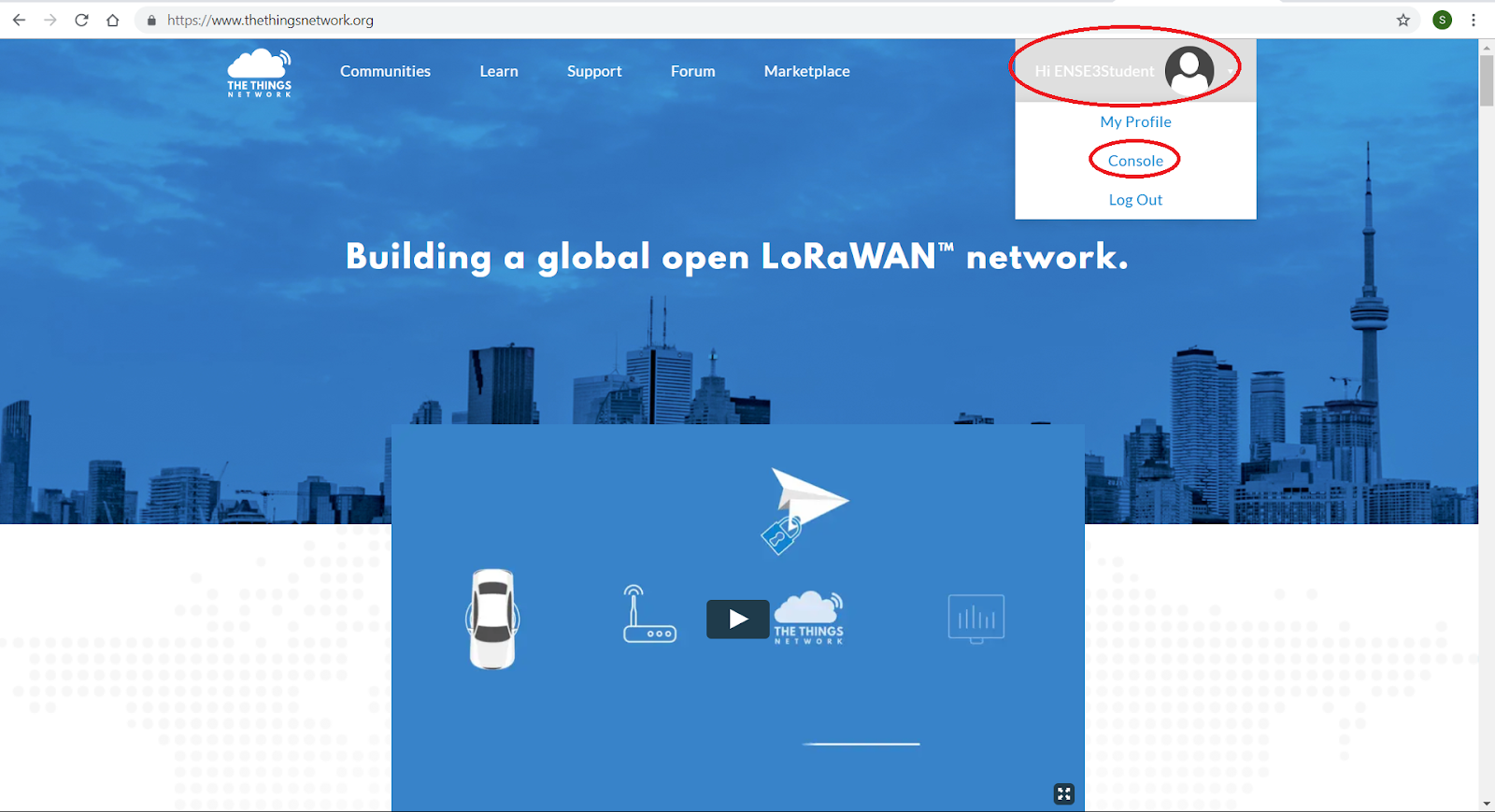
Pour ce faire, nous allons créer un compte à l’adresse suivante :
https://account.thethingsnetwork.org/register
Une fois votre compte créé, connectez vous, sur la page d’accueil, cliquez sur votre profil en haut à droite puis cliquez sur console puis enfin choisissez application :
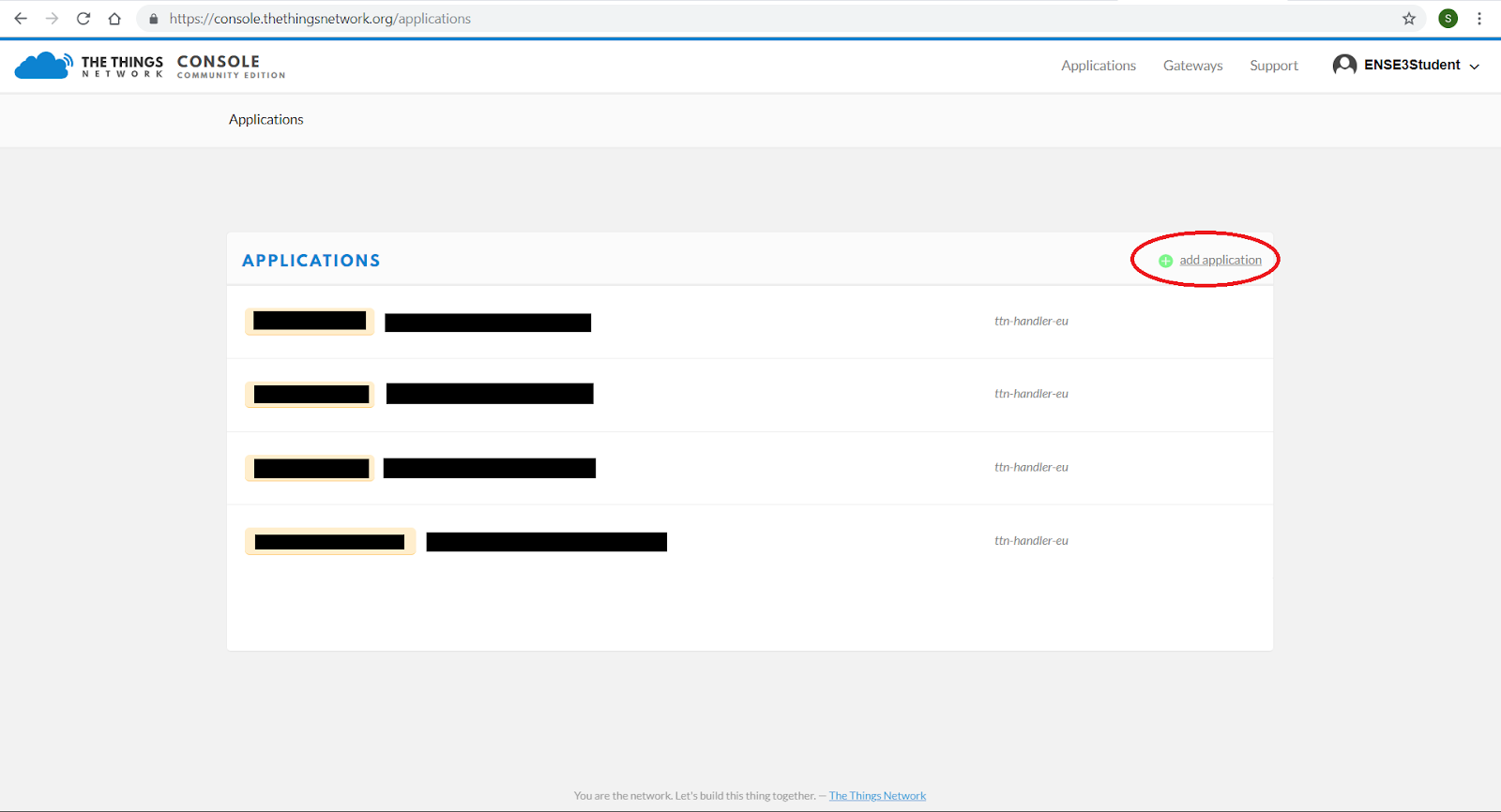
Maintenant vous pouvez créer votre application avec un serveur tampon de 7 jours. Pour cela, cliquez sur « add application ».
Choisissez un nom dans « Application ID », ajoutez un descriptif une fois ces champs rempli, vous pouvez cliquez sur « Add application » une nouvelle fois.
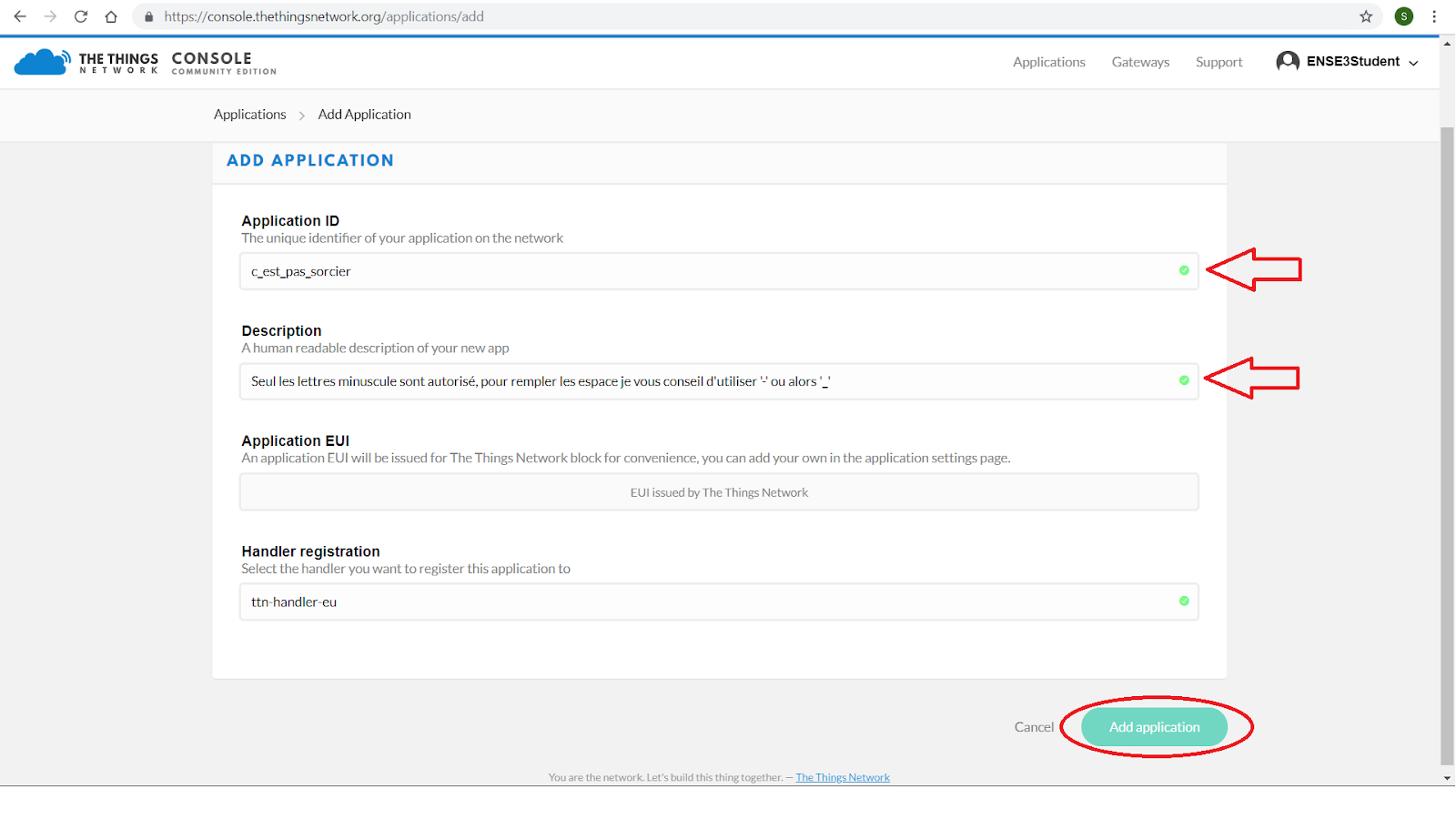
Cliquez sur l’application » que vous venez de créer désormais, plusieurs informations seront affichées.
Nous allons avoir besoin de certains d’entre elles pour compléter le code précédent.
Pour ce faire nous devons aller dans l’onglet « Devices » et cliquer sur « Get started by registering one! » ou « register device »
Une fois cela fait, il ne vous restera plus qu’à entrer un nom dans « Device ID » ainsi que de cliquez sur les doubles flèches à gauche des champs prévus pour insérer le texte :
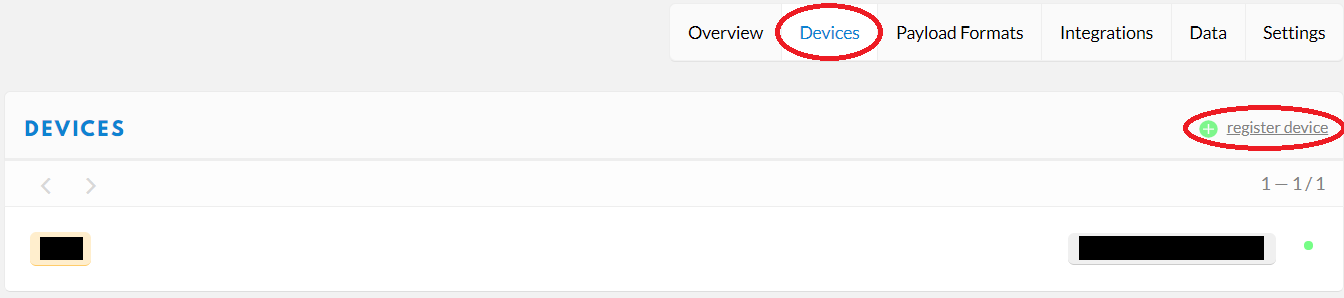
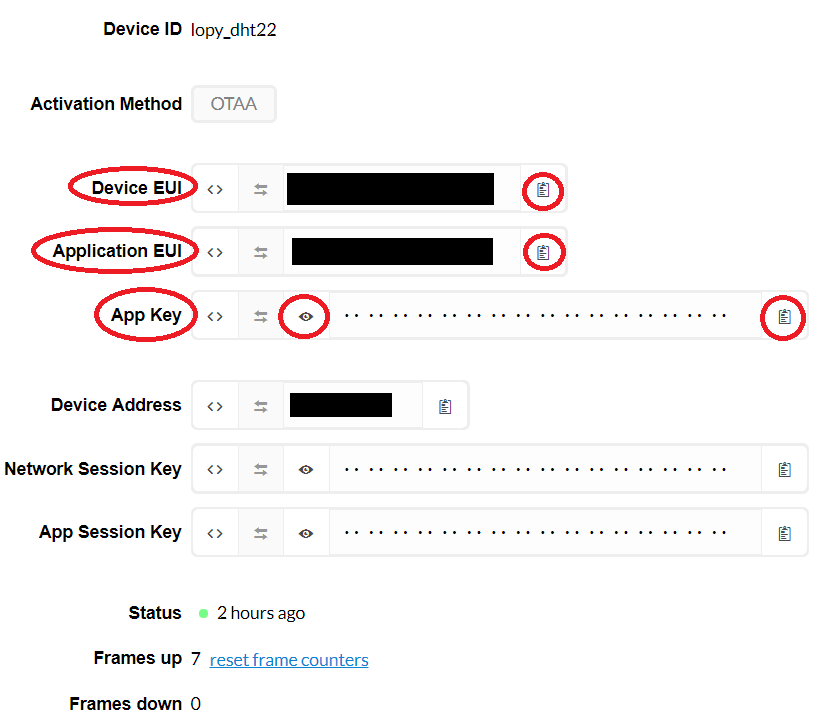
Une fois cela fait, cliquez sur register en bas à droite de la page. Ce qui vous renverra sur une page contenant plein de chiffres et de lettres. C’est sur cette page là que nous allons trouver les informations nécessaires pour compléter notre code.
Dans le code copié précédemment vous avez remarqué qu’à la ligne 24,25 et 26 des informations sont manquantes.
Pour la ligne 24 entre les simples quotes (‘), il vous faudra mettre la suite de chiffre et de lettre contenu dans la case à côté de « Device EUI » pour éviter que cela soit monotone et éliminer le risque d’erreur je vous conseille d’utiliser le bouton situé à droite de la case permettant de copier le contenu dans la case en 1 clic! Cela fonctionnera également pour les 2 prochains contenus à copier.
Pour la ligne 25, entre les simples quotes (‘), il vous faudra mettre le contenu de la case à côté de « Application EUI ».
Pour la ligne 26 entre les simples quotes (‘), il vous faudra mettre le contenu dans la case à côté de « App Key » (Pensez à appuyer sur l’oeil à gauche de cette case pour voir les chiffres et les lettres contenu dans celle ci mais avec la technique citée précédemment, il n’est pas nécessaire de voir le texte pour le copier).
PARTIE 5: PROGRAMMATION DE LA LOPY
Désormais, vous pouvez mettre votre code dans la Pycom Lopy pour se faire nous allons utiliser Atom qui un éditeur de texte OpenSource avec son paquet Pymakr, ce paquet supplémentaire nous permettra de communiquer avec notre Lopy et télécharger votre projet, vos fichiers contenant le code python précédent sur votre Nano Ordinateur.
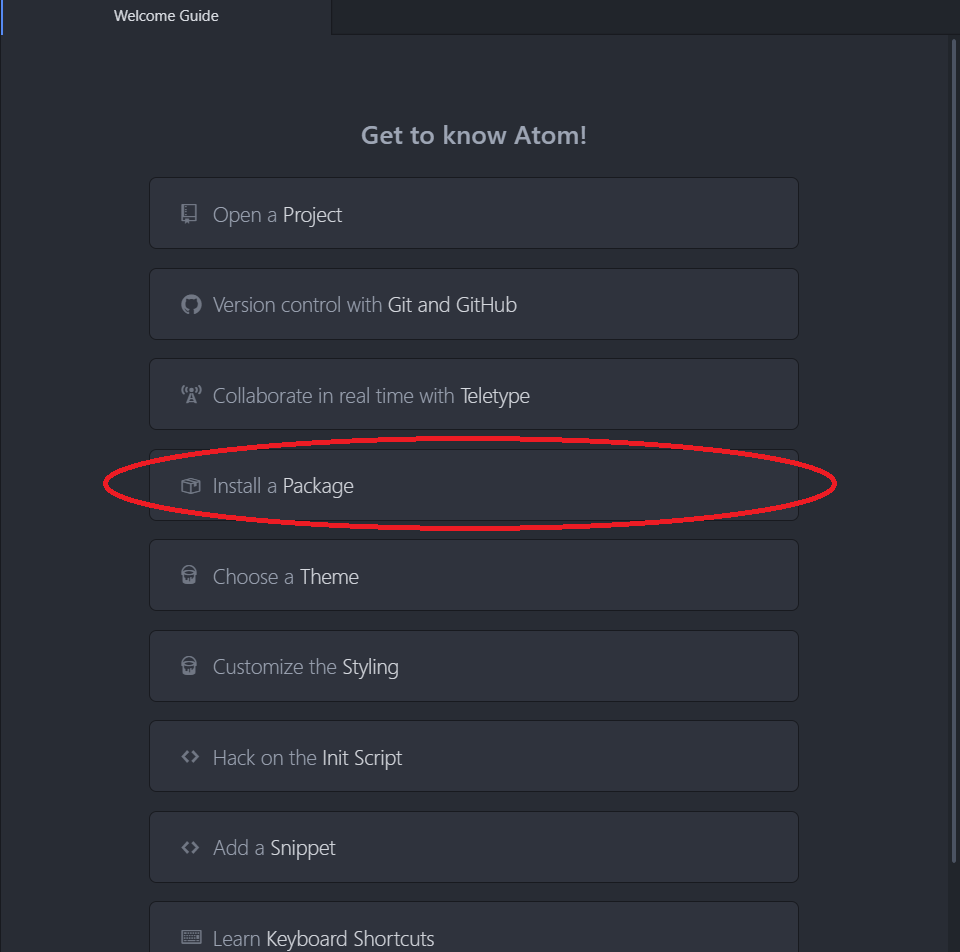
Vous pouvez télécharger Atom en cliquant sur “Download” sur cette page :
ou alors directement en cliquant sur ce lien si vous vous trouvez sous windows 64bits :
https://atom.io/download/windows_x64
Vous pouvez télécharger Atom directement en cliquant sur ce lien si vous vous trouvez sous Linux :
Pour installer Pymakr, vous devez premièrement lancer Atom puis cliquer sur « Install a Package » à droite de votre application parmi la colonne de choix proposés. Enfin cliquez sur « Open Installer » puis cherchez « pymakr », il s’agira du premier de la liste normalement, téléchargez le module en appuyant sur le bouton prévu à cet effet.

Une fois l’installation terminée, vous avez une fenêtre « terminal » qui s’ouvre au sein de votre Atom, pas d’inquiétude cela veut tout simplement dire que vous avez réussi à installer Pymakr.
Désormais nous allons connecter notre Pycom en wifi au PC si cela n’était pas déjà fait auparavant alors vous devez avoir une ligne indiquant « Connecting on AdresseIpDeVotrePycom ».
Si c’est le cas alors tout va bien jusque là et on est presque au bout de notre périple pour installer notre capteur DHT22 et récupérer toutes ses précieuses données.
Désormais, il ne vous restera plus qu’à ouvrir votre dossier contenant les code python main.py, et boot.py.
Pour ce faire, appuyez simultanément sur les touches Ctrl + Shift + A puis sélectionnez donc notre dossier, validez puis enfin vous cliquerez sur « Package » puis sélectionnez dans la liste proposée « Pymakr » et enfin cliquez sur « synchronize project ».
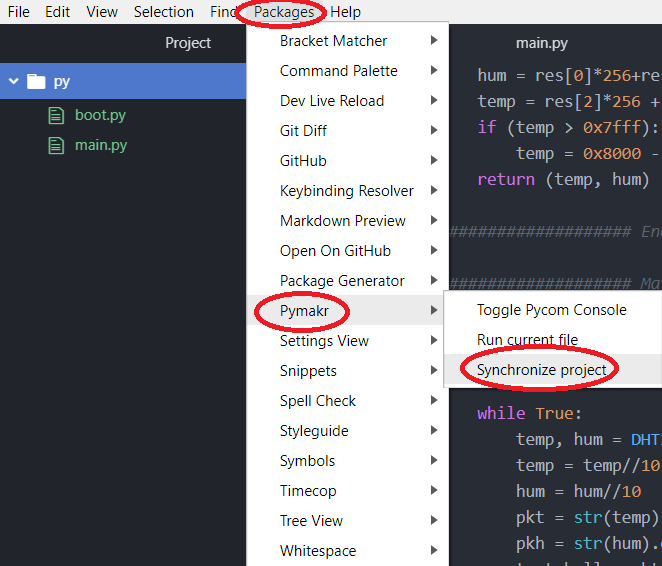
Il est également possible en fonction de votre version d’Atom de cliquez sur « Upload » qui se situe au dessus à droite de votre fenêtre « terminal » qui c’est ouverte dans Atom.
Grâce à cette action votre Lopy recevra le code et l’exécutera. Le code étant prévu dans une boucle while infinie, notre code tournera en boucle désormais jusqu’à la fin des temps.
Vous pouvez également utiliser l’option « Run » mais celle ci permet d’exécuter le programme jusqu’à que votre Pycom s’éteigne (ou qu’elle n’est plus d’alimentation), tandis que « Upload » permet de dire à la carte de continuer à exécuter le code tant que l’on n’a pas remplacé celui-ci dans la carte ou de la réinitialiser.
Pour information, si vous regardez votre code de plus près, on se rend compte qu’il met en « veille » la transmission des données récoltées par le capteur pendant 304 secondes soit 5 minutes et 04 secondes, pourquoi 04 secondes ? Tout simplement car je n’aime pas les chiffres rond et si vous voulez modifiez cette valeurs, il vous suffira de modifier la valeurs comprise entre les parenthèses // () qui suivent notre « time.sleep » à la ligne 125, qui est exprimé en seconde, il faudra également ajouter 4 secondes à ce temps là, qui est un peu éparpillé ailleurs dans le code mais je doute fort que vous ayez envie de voir la température et l’humidité variées avec moins de 4 secondes d’intervalles entre chaque valeurs ce qui n’aurait pas grand intérêt dans le domaine abordé actuellement.

Désormais notre Lopy permet de transmettre les données du capteur DHT22 à TheThingsNetwork.
PARTIE 6: DÉTRAMAGE DES DONNÉES SUR TTN
Si on retourne sur le site web : https://console.thethingsnetwork.org/applications en choisissant votre application et en allant dans l’onglet « Data » rien n’apparaît, vous n’avez qu’un tableau rempli d’une couleur bleu clair et transparent et sans colonne.
Pourtant, je vous assure que les données sont transmises et TheThingsNetwork les reçoit bien !
Mais pourtant tout reste vide…
Si vous cliquez sur l’onglet « Payload Formats » vous verrez encore du code mais cette fois ci, il est commenté et forcément si un code est en commentaire, il ne sera pas lu et ne pourra pas faire la tâche qui lui est attribué…
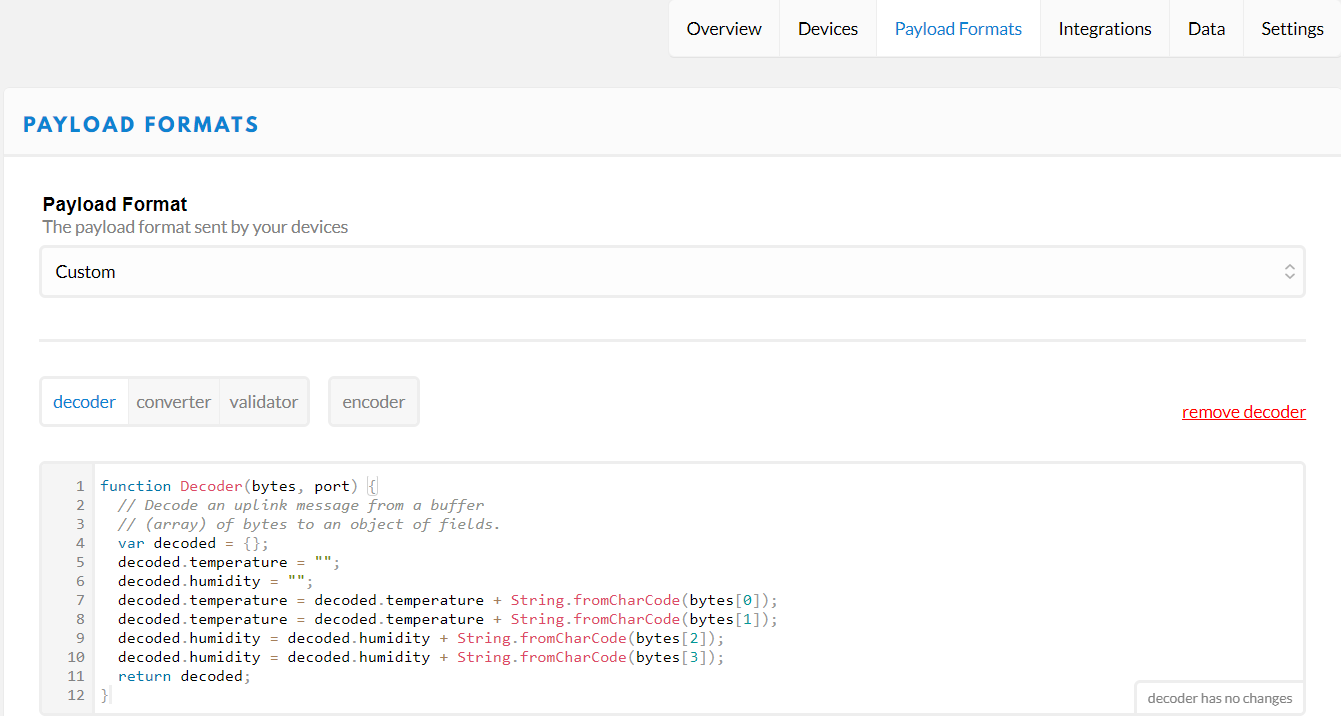
Cette fois-ci, vous allez devoir copier ce code :
function Decoder(bytes, port) {
// Decode an uplink message from a buffer
// (array) of bytes to an object of fields.
var decoded = {};
decoded.temperature = "";
decoded.humidity = "";
decoded.temperature = decoded.temperature + String.fromCharCode(bytes[0]);
decoded.temperature = decoded.temperature + String.fromCharCode(bytes[1]);
decoded.humidity = decoded.humidity + String.fromCharCode(bytes[2]);
decoded.humidity = decoded.humidity + String.fromCharCode(bytes[3]);
return decoded;
}et le coller à la place de tout ce qui se trouve dans la fenêtre qui contient du code en commentaire.
Maintenant, si on regarde dans l’onglet « Data » on verra les données arriver toutes les 5 minutes et 04 secondes.

Il ne reste plus qu’à créer un « Data Storage » dans TheThingsNetwork.
PARTIE 7 : SERVEUR TAMPON SUR TTN
Pour ce faire, on va aller dans l’onglet « Integration », une fois dans cette onglet, on va cliquer sur « Get started by creating one! » ou « add integration », cela nous conduit sur une nouvelle page. Sur celle-ci, on va sélectionner « Data Storage », une fois cela fait, on valide en cliquant sur « add integration » en bas à droite puis enfin on va cliquez sur « go to platform ».
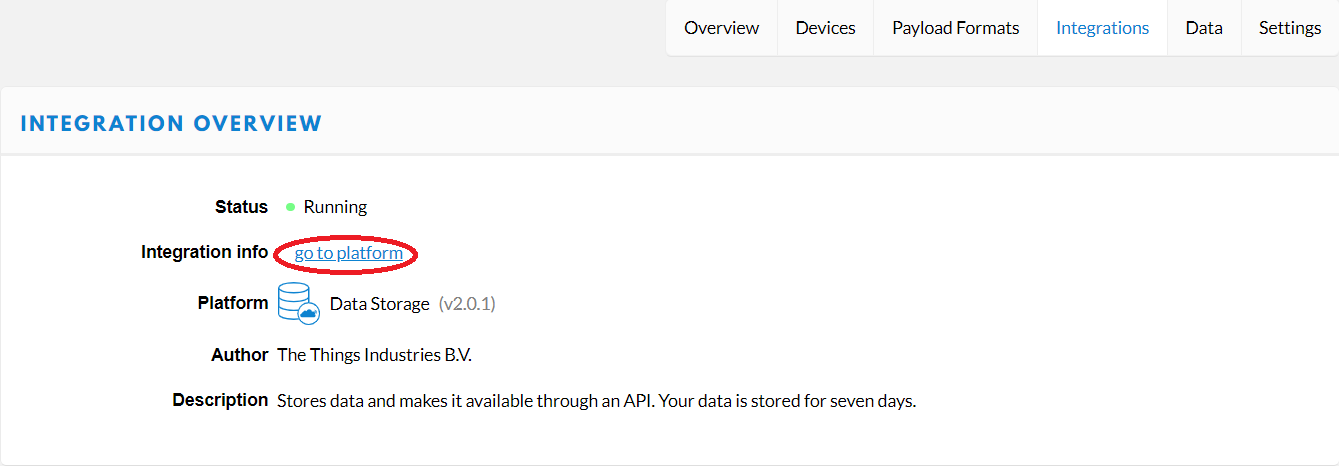
Le Data Storage existe, et en ayant cliquez sur « go to platform » une nouvelle fenêtre dans le navigateur c’est ouverte.
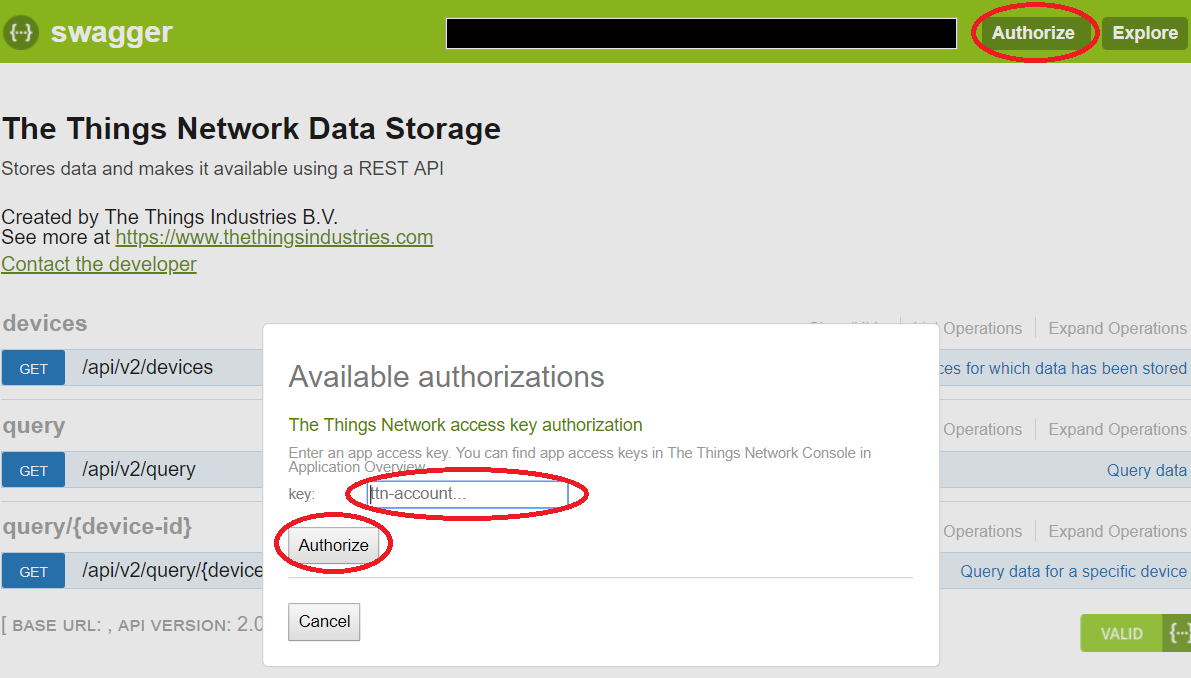
Retournons sur notre autre fenêtre et allons dans l’onglet « Overview » et descendez tout en bas de cette page, copier le contenu de « ACCESS KEYS » :

Une fois le contenu copié, on retourne sur notre fenêtre qui s’est ouverte précédemment, et tout en haut à droite dans la barre verte se trouve « Authorize », cliquez dessus, collez ce que vous venez de copier dans le cadre puis cliquez sur “Authorize” :
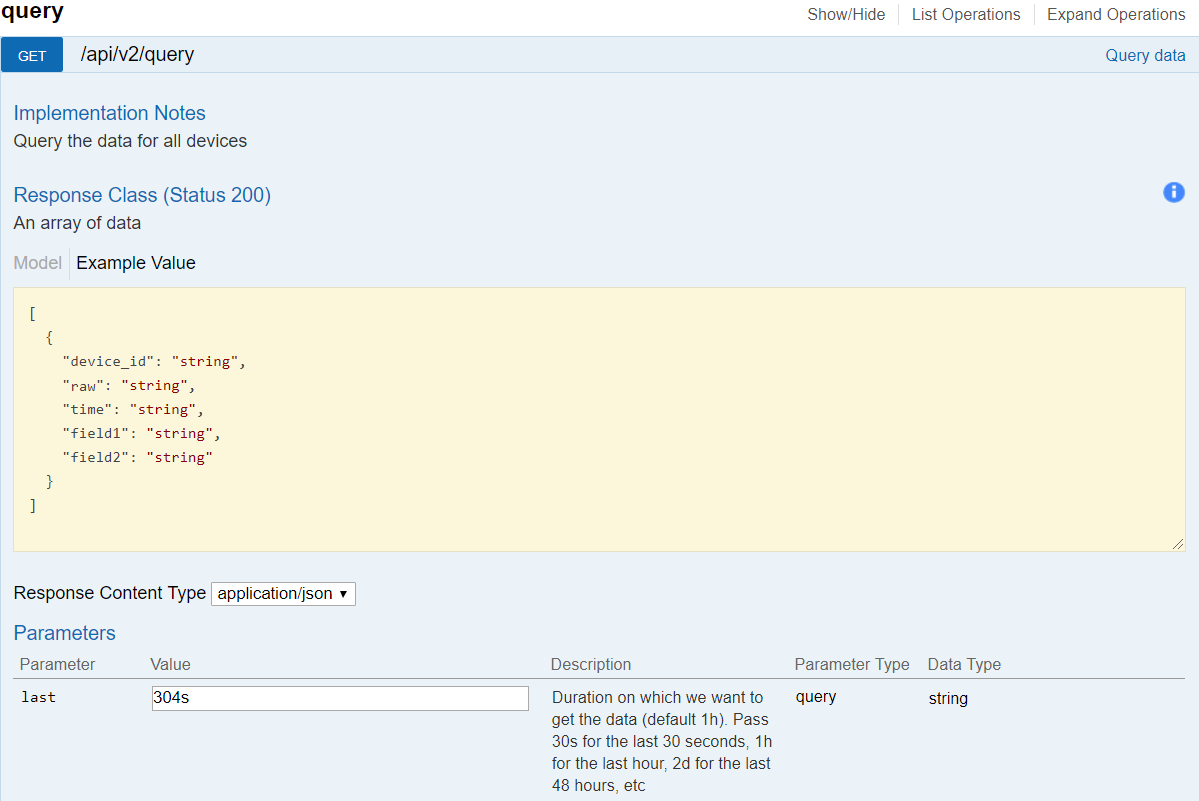
Cliquez sur « /api/v2/query » et dans le cadre demandant les paramètres écrivez « 304s », validez.
On va désormais, faire un moyen de stockage qui durera plus de 7 jours et qui soit permanent.
PARTIE 8: STOCKAGE DANS UNE BASE DE DONNÉES PERMANENTE INFLUXDB
Pour cette partie, on va installer InfluxDB.

InfluxDB c’est quoi ?
Il s’agit d’un outil de gestion de Base De Données qui rentre dans la famille des Base De Données (BDD) tel que MariaDB ou encore MySQL mais les commandes et les noms ne seront pas tout à fait les mêmes, tout comme la structure au final.
Pour l’installer, il suffit d’utiliser cette commande dans votre terminal:
sudo apt-get update; sudo apt-get upgrade; sudo apt-get install influxdb; sudo service influxdb start

Si vous faite régulièrement vos mises à jours, cela ne durera pas longtemps.
Cette commande nous permet de mettre à jour notre OS, d’installer InfluxDB puis enfin de le lancer sans intervention de notre part, sauf si les fichiers à télécharger sont volumineux et à ce moment là ils nous demandent une petite confirmation de votre part par un ‘O’ ou ‘Y’.
Maintenant que InfluxDB est installé, on va quand même vérifier que tout marche bien.
Pour ça, on va utiliser la commande « influx » qui va nous permettre de nous connecter à InfluxDB.
Si tout est ok, votre terminal change légèrement et ressemble à cela :

Maintenant qu’on a vérifié que tout marche, on va quitter InfluxDB pour se lancer dans un script en langage C et Shell pour automatiser la réception de nos données.
Pour quitter InfluxDB, on va utiliser la commande « quit ». Une fois InfluxDB quitté, nous revoilà sur le Terminal d’origine.
Vous pouvez récupérer les codes que l’on va aborder dans ce fichier zip suivant:
zip C
Avant de commencer, on va créer un dossier qui aura pour nom : GestionDHT22 dans le dossier Documents

On va désormais créer 3 nouveaux scripts, le premier qui s’appellera : script_shell_BDD.sh qui lui contiendra ce script là :
#!/bin/bash
cd ~/Documents/GestionDHT22
curl -i -XPOST 'http://localhost:8086/write?db=nom_de_votre_BDD' --data-binary @testtend.txt
rm *.txtIl nous permettra d’envoyer le contenu de “testtend.txt” à notre BDD InfluxDB ainsi que de supprimer tous les fichiers .txt créés durant l’exécution du programme C afin de permettre le traitement des données.
Un deuxième : script_shell_curl.sh qui lui aura pour code :
#!/bin/bash
cd ~/Documents/GestionDHT22Nous devons retourner sur notre fameuse page internet et récupérer la commande « Curl » pour l’insérer ici (exemple ci dessous) :
#curl -X GET –header ‘Accept: application/json’ –header ‘Authorization: key ttn-account-v2.suite_de_caractere’ ‘https://nom_de_votre_application.data.thethingsnetwork.org/api/v2/query?last=304s’ > testtr.txt
Ajoutez également à la fin de cette commande Curl « > testtr.txt » comme montrez dans l’exemple ci dessus, cela nous permettra de rediriger la sortie de ce que notre commande écrit dans le terminal dans le fichier testtr.txt
Celui ci nous permettra de récupérer les valeurs en format Json de la page venant du Data Storage de TheThingsNetwork
Enfin le dernier et aussi le plus long : unJolieNom.c qui lui contiendra ce code là :
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#define LECTURE_MAX 1000000
int main()
{
FILE* ficr;
FILE* ficw;
FILE* ficp;
FILE* ficx;
FILE* ficfull;
FILE* fice;
FILE* ficl;
char jsonOneLigne[LECTURE_MAX] = "";
int a;
int compt;
int savecompt;
char jsonPretty[LECTURE_MAX] = "";
int i;
int try;
char traiter[LECTURE_MAX] = "";
int n;
while (1)
{
system("sh script_shell_curl.sh");
strcpy(jsonOneLigne,"");
ficr = NULL;
ficr = fopen("testtr.txt", "r");
if (ficr == NULL)
{
printf("Une erreur c\'est produit durant l'ouverture du fichier de lecture");
exit(1);
}
else
{
fgets(jsonOneLigne, LECTURE_MAX, ficr);
fclose(ficr);
ficw = NULL;
ficw = fopen("testtw.txt", "w");
if (ficw == NULL)
{
printf("Une erreur c\'est produit durant l'ouverture du fichier d\'ecriture");
exit(1);
}
else
{
a = 0;
compt = 0;
savecompt = compt;
while (jsonOneLigne[a] != '\0')
{
if (jsonOneLigne[a] == '[')
{
if (a != 0)
{
fprintf(ficw, "\n");
}
fprintf(ficw, "%c", jsonOneLigne[a]);
compt++;
}
else if (jsonOneLigne[a] == '"' && jsonOneLigne[a-1] == '[')
{
savecompt = compt;
fprintf(ficw, "\n");
while (compt != 0)
{
fprintf(ficw, "\t");
compt--;
}
fprintf(ficw, "%c", jsonOneLigne[a]);
compt = savecompt;
compt++;
savecompt = compt;
}
else if (jsonOneLigne[a] == ']')
{
fprintf(ficw, "\n%c", jsonOneLigne[a]);
compt--;
}
else if (jsonOneLigne[a] == '{')
{
savecompt = compt;
fprintf(ficw, "\n");
while (compt != 0)
{
fprintf(ficw, "\t");
compt--;
}
fprintf(ficw, "%c", jsonOneLigne[a]);
compt = savecompt;
compt++;
savecompt = compt;
fprintf(ficw, "\n");
while (compt != 0)
{
fprintf(ficw, "\t");
compt--;
}
compt = savecompt;
}
else if (jsonOneLigne[a] == '}')
{
compt--;
savecompt = compt;
fprintf(ficw, "\n");
while (compt != 0)
{
fprintf(ficw, "\t");
compt--;
}
compt = savecompt;
fprintf(ficw, "%c", jsonOneLigne[a]);
}
else if (jsonOneLigne[a] == ':')
{
fprintf(ficw, "%c", jsonOneLigne[a]);
if (jsonOneLigne[a] == ':' && jsonOneLigne[a+1] == '"')
{
fprintf(ficw, " ");
}
}
else if (jsonOneLigne[a] == ',' && jsonOneLigne[a+1] == '{')
{
fprintf(ficw, "%c", jsonOneLigne[a]);
}
else if (jsonOneLigne[a] == ',')
{
savecompt = compt;
fprintf(ficw, "%c\n", jsonOneLigne[a]);
while (compt != 0)
{
fprintf(ficw, "\t");
compt--;
}
compt = savecompt;
}
else
{
fprintf(ficw, "%c", jsonOneLigne[a]);
}
a++;
}
}
fclose(ficw);
ficp = NULL;
ficp = fopen("testtw.txt", "r");
if (ficp == NULL)
{
printf("Une erreur c\'est produit durant l'ouverture du fichier de lecture");
exit(1);
}
else
{
ficx = NULL;
ficx = fopen("testt.txt", "w");
ficfull = NULL;
ficfull = fopen("testtfull.txt", "a");
if (ficx == NULL || ficfull == NULL)
{
printf("Une erreur c\'est produit durant l'ouverture du fichier d\'ecriture");
exit(1);
}
else
{
strcpy(jsonPretty,"");
while (fgets(jsonPretty,LECTURE_MAX, ficp) != '\0')
{
printf("%s", jsonPretty);
i = 0;
try = 0;
while (jsonPretty[i] != '\0')
{
if (jsonPretty[i] >= 'a' && jsonPretty[i] <= 'z')
{
fprintf(ficx, "%c", jsonPretty[i]);
fprintf(ficfull, "%c", jsonPretty[i]);
}
if (jsonPretty[i] >= 'A' && jsonPretty[i] <= 'Z')
{
fprintf(ficx, "%c", jsonPretty[i]);
fprintf(ficfull, "%c", jsonPretty[i]);
}
if (jsonPretty[i] == ':' || jsonPretty[i] == '.')
{
if (jsonPretty[i] == ':' && jsonPretty[i+1] == ' ')
{
fprintf(ficx, "%c", jsonPretty[i]);
fprintf(ficfull, "%c", jsonPretty[i]);
fprintf(ficx, "%c", jsonPretty[i+1]);
fprintf(ficfull, "%c", jsonPretty[i+1]);
}
else
{
fprintf(ficx, "%c", jsonPretty[i]);
fprintf(ficfull, "%c", jsonPretty[i]);
}
}
if (jsonPretty[i] == '\n' || jsonPretty[i] == '=' || jsonPretty[i] == '_' || jsonPretty[i] == '-')
{
fprintf(ficx, "%c", jsonPretty[i]);
fprintf(ficfull, "%c", jsonPretty[i]);
}
if (jsonPretty[i] <= '9' && jsonPretty[i] >= '0')
{
fprintf(ficx, "%c", jsonPretty[i]);
fprintf(ficfull, "%c", jsonPretty[i]);
}
i++;
}
}
fclose(ficp);
}
fclose(ficx);
fclose(ficfull);
fice = NULL;
fice = fopen("testtend.txt", "w");
if (ficp == NULL)
{
printf("Une erreur c\'est produit durant l'ouverture du fichier d'ecriture");
exit(1);
}
else
{
ficl = NULL;
ficl = fopen("testt.txt", "r");
if (ficl == NULL)
{
printf("Une erreur c\'est produit durant l'ouverture du fichier de lecture");
exit(1);
}
else
{
strcpy(traiter,"");
fprintf(fice, "captor_tester,capteur_numero=1 ");
while (fgets(traiter,LECTURE_MAX, ficl) != '\0')
{
n = 0;
if (traiter[0] == 't' && traiter[1] == 'e' && traiter[2] == 'm' && traiter[3] == 'p' && traiter[4] == 'e' && traiter[5] == 'r' && traiter[6] == 'a' && traiter[7] == 't' && traiter[8] == 'u' && traiter[9] == 'r' && traiter[10] == 'e')
{
fprintf(fice, ",");
}
while (traiter[n] != '\0')
{
if (traiter[0] == 't' && traiter[1] == 'i' && traiter[2] == 'm' && traiter[3] == 'e')
{
while (traiter[n] != '\0')
{
n++;
}
}
if (traiter[0] == 'd' && traiter[1] == 'e' && traiter[2] <= 'v' && traiter[3] >= 'i' && traiter[4] <= 'c' && traiter[5] >= 'e')
{
while (traiter[n] != '\0')
{
n++;
}
}
if (traiter[0] == 'r' && traiter[1] == 'a' && traiter[2] == 'w')
{
while (traiter[n] != '\0')
{
n++;
}
}
if (traiter[n] <= 'Z' && traiter[n] >= 'A')
{
fprintf(fice, "%c", traiter[n]);
}
else if (traiter[n] <= 'z' && traiter[n] >= 'a')
{
fprintf(fice, "%c", traiter[n]);
}
else if (traiter[n] == ':' && traiter[n+1] == ' ')
{
fprintf(fice, "=");
}
else if (traiter[n] == '_' || traiter[n] == '-' || traiter[n] == '.' || traiter[n] == ':' || traiter[n] == '\'')
{
fprintf(fice, "%c", traiter[n]);
}
else if (traiter[n] <= '9' && traiter[n] >= '0')
{
fprintf(fice, "%c", traiter[n]);
}
else if (traiter[n] == '=')
{
fprintf(fice, "%c", traiter[n]);
}
n++;
}
}
fclose(ficl);
}
}
fclose(fice);
}
}
system("sh script_shell_BDD.sh");
sleep(300);
}
return (0);
}
Enfin vous utiliserez la commande suivante:
gcc ./unJolieNom.c
Celle-ci, nous permet de rendre notre code C compréhensible par la machine, elle a convertie votre code C en exécutable.
Une fois cela fait, pour l’exécuter, il ne vous reste plus qu’à faire lancer cette dernière commande:
./a.out
cela lancera le programme compilé sans aucune extension qui se nomme : a.out par défaut.

Voilà, notre script nous permet de récupérer toutes les 5 minutes et 04 secondes les valeurs transmises par le capteur, cela nous permet d’avoir la même fréquence que l’envoi des données de notre capteur DHT22.
Il ne vous reste plus qu’à lancer ce script sur votre machine ou même sur une Raspberry si vous ne voulez pas laisser votre Ordinateur allumé en permanence.
Mais si vous avez un souci,( que votre Ordinateur s’éteint ou que le script cesse de fonctionner) et que vous perdez 1,2,3,4,5,6 voir 7 jours (car vous êtes partis en vacances par exemple), il vous suffira d’effectuer une petite modification afin de nous permettre de récupérer tout cela d’un seul coup.
Je vous conseille même de faire des fichier « Origine » permettant de garder les codes d’origines pour être sûr de ne pas vous tromper lors de la remise par défaut de votre code. Vous n’aurez qu’à faire un copier/coller de ces derniers pour reprendre comme avant vos activités de stockage.
Donc la modification à faire est sur la commande Curl du script_shell_curl, à la fin de celle ci se trouve « =304s » si vous avez mis également un temps de 304 secondes entre chaque mesure. Vous devrez mettre si vous avez perdu 10 heures 25 minutes 2 secondes par exemple « =37502s » mais si vous avez besoin de récupérer précisément 1 jours vous pouvez également mettre « =1d » ou qu’une seul heure « =1h » mais en générale, on ne perd pas 1 journée précise de travail alors je vous conseille de faire une conversion en secondes pour récupérer absolument toutes les valeurs perdues.

Une fois la modification faite, lancez le programme normalement et une fois exécuté une fois, vous pouvez le remettre avec votre temps précédemment dans notre cas « =304s ».
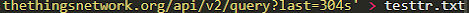
Et voilà, désormais InfluxDB nous permet le stockage à long termes de nos valeurs reçues et même de récupérer les données perdues jusqu’à 1 semaine si votre serveur a décidé de vous laisser tomber en même temps que vos vacances.
Mais je pense que nous sommes tous d’accord pour dire qu’un affichage graphique permettant un aperçu plus simpliste et plus lisible serait également sympathique pour visualiser nos données stockées sans difficulté afin de voir plus rapidement certaines anomalies pour les analyser par exemple ou encore permettre de voir entre quelle valeurs oscille notre température et notre humidité dans notre cas.
Pour ce faire on va utiliser Grafana.
PARTIE 9: VISUALISATION DES DONNÉES VIA GRAFANA
Grafana c’est quoi ?

Grafana c’est un logiciel libre, il est OpenSource, il est disponible sous license Apache 2.0.
Il permet la visualisation et la mise en forme de diverses données au sein de divers tableaux de bord graphiques. Il supporte plusieurs sources dont des Bases De Données comme OpenTSDB, graphite ou encore InfluxDB, parfait c’est exactement ce que vous utilisez !
Comment l’installer ?
Si vous êtes sous Linux :
Soit vous pouvez l’installer de manière classique avec non pas 1 mais 2 lignes de commande et le tour sera joué.
sudo wget https://dl.grafana.com/oss/release/grafana_6.2.5_amd64.deb
sudo dpkg -i grafana_6.2.5_amd64.deb

Une fois cela fait, il vous suffit de lancer cette commande qui permettra de mettre en route le serveur grafana :
sudo /bin/systemctl start grafana-server
Si vous êtes sous windows :
Cliquez sur le lien suivant pour installer l’installation de grafana.
https://dl.grafana.com/oss_release/grafana-6.2.5.windows-amd64-msi
Une fois installé, lancer le.
Laissez tout par défaut en suivant ce qui vous est demandé lors de l’installation.
Si vous êtes sous mac :
Une seule ligne de commande suffira :
brew install grafana
Une fois cela fait il vous suffit de lancer cette commande qui permettra de lancer le serveur grafana :
brew services start grafana.
Une fois l’installation terminée, ouvrez un navigateur web et allez sur le lien suivant :

Une fois sur cette page, il vous sera demandé un nom d’utilisateur et un mot de passe, les 2 seront par défaut « admin »
Une fois connecté, on vous demandera si vous souhaitez changer de mot de passe, ce qui est fortement recommandé…
Maintenant qu’il est installé et fonctionnel, il ne reste plus qu’à le configurer.
Pour ce faire, une fois connecté, en haut à gauche dans une liste vertical se trouver un « + » cliquez dessus puis sélectionner sur « Dashboard ».

Je vous conseille d’utiliser « Choose Visualization » dans un premier temps utilisez l’option « Graph » pour permettre l’affichage de votre température et de votre humidité sur le même graphique. Une fois « Graph » sélectionné, plusieurs options vous sont proposées. Pour plus de clarté, je vous suggère d’utiliser « Lines » qui vous permettra comme son nom l’indique de former une lignes constante grâce aux différentes valeurs récoltées.

Utiliser « Bars » permet de créer une barre verticale pour chaque valeur récoltée, ce qui permet de voir la valeur reçue ainsi que sa temporalité.

Enfin utilisez « Points » vous permet de créer 1 point par valeur ce qui à mon sens n’a pas forcément d’intérêt dans notre situation, je vous conseille donc d’utiliser « Lines » ou bien « Bars ».

Ensuite dans la colonne « Mode Options », si vous avez sélectionné l’option « Bars », aucune option dans cette colonne ne vous sera proposée. Si vous avez sélectionné l’option « Lines », l’option « Fill » permet de choisir l’opacité de ce qui se trouve en dessous de votre ligne, elle est par défaut réglé à 1 et je vous conseille de garder cette valeur. L’option « Line Width » permet de régler l’épaisseur de la ligne, elle est également fixé à 1 par défaut. L’option « Staircase » permet de mettre un mode escalier, cela permettra un mélange entre l’option « Lines » et l’option « Bars ». Si vous avez sélectionné l’option « Points », Seule l’option « Point Radius » vous sera proposée, vous permettant de choisir la taille du rayon de votre point.
Ensuite dans la colonne « Hover tooltip », Il ne faudra rien toucher.
Dans la colonne « Stacking & Null value », il faudra mettre « Null value » avec pour valeur « null » ce qui permettra en cas d’erreur de ne pas renvoyer une valeur aberrante tel que 0 qui est proposée dans la liste des valeurs assignable à « Null value ».
Une fois la partie visuelle terminée, on va descendre légèrement et donner des titres à nos Axes. D’autant plus que nous allons avoir besoin des 2 axes Y pour mettre l’humidité et la température sur le même graphique.
Nous allons mettre la température à gauche et l’humidité à droite en assignant les extremums possible par le capteurs.
Ensuite vient la légende, cela ne dépend que de vous. Pour ma part, je continuerai en activant « Show », « As Table » ainsi que « To the right ».

Désormais, on va cliquer sur le boulon avec la clé à molette dans la colonne de gauche qui s’appelle « General”

On va activer le mode « Transparent » pour plus de confort lors de la lecture des futures valeurs.
Une fois tout cela fait, on sauvegarde en appuyant le boulon tout en haut de l’écran qui s’appelle « Dashboard settings »
Puis cliquez sur « save », à ce moment là, on donne le nom du tableau de bord que l’on souhaite. On va ensuite aller dans Dashboard (le carré découpé en 4 petit carré (à gauche de votre écran).

Puis cliquez sur « Add data source », on sélectionne notre outil de gestion de Base De Données soit, InfluxDB.

Ensuite on cliquera sur la case « URL » et on prendra le lien proposé comme ci-dessous ou si il n’est pas proposé copier le :
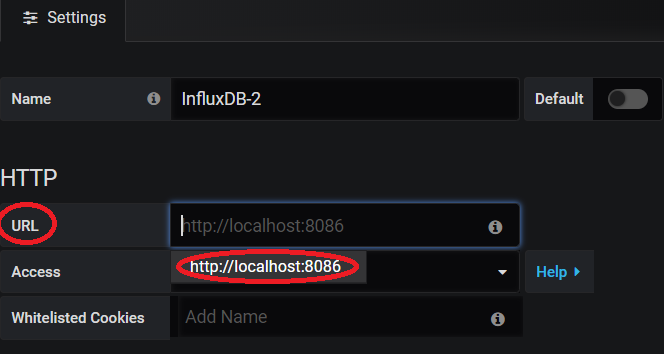
Il ne vous reste plus qu’à renseigner le nom de votre Base De Données créé précédemment dans la case « Database ».
Et voilà, il ne vous reste plus qu’à cliquer sur « Save & Test » tout en bas de la page pour valider votre Base De Données au sein de Grafana. Désormais vous pourrez utiliser les valeurs présentes dans cette Base De Données sur Grafana sur tous vos dashboard.
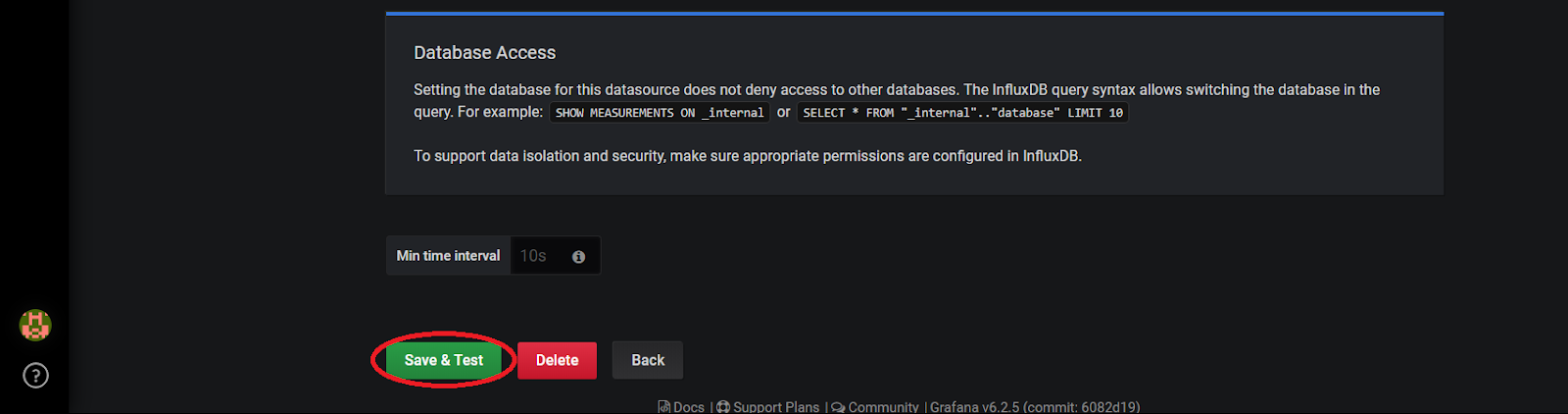
Retournons sur notre page d’accueil « Dashboard ».

Vous aurez une ligne ayant le nom du dashboard que vous venez de sauvegarder.
Cliquez dessus

Une fois de retour sur la page, mettez votre souris sur votre graphique et appuyez sur la touche « e », cela ouvrira le panneau d’édition du graphique.
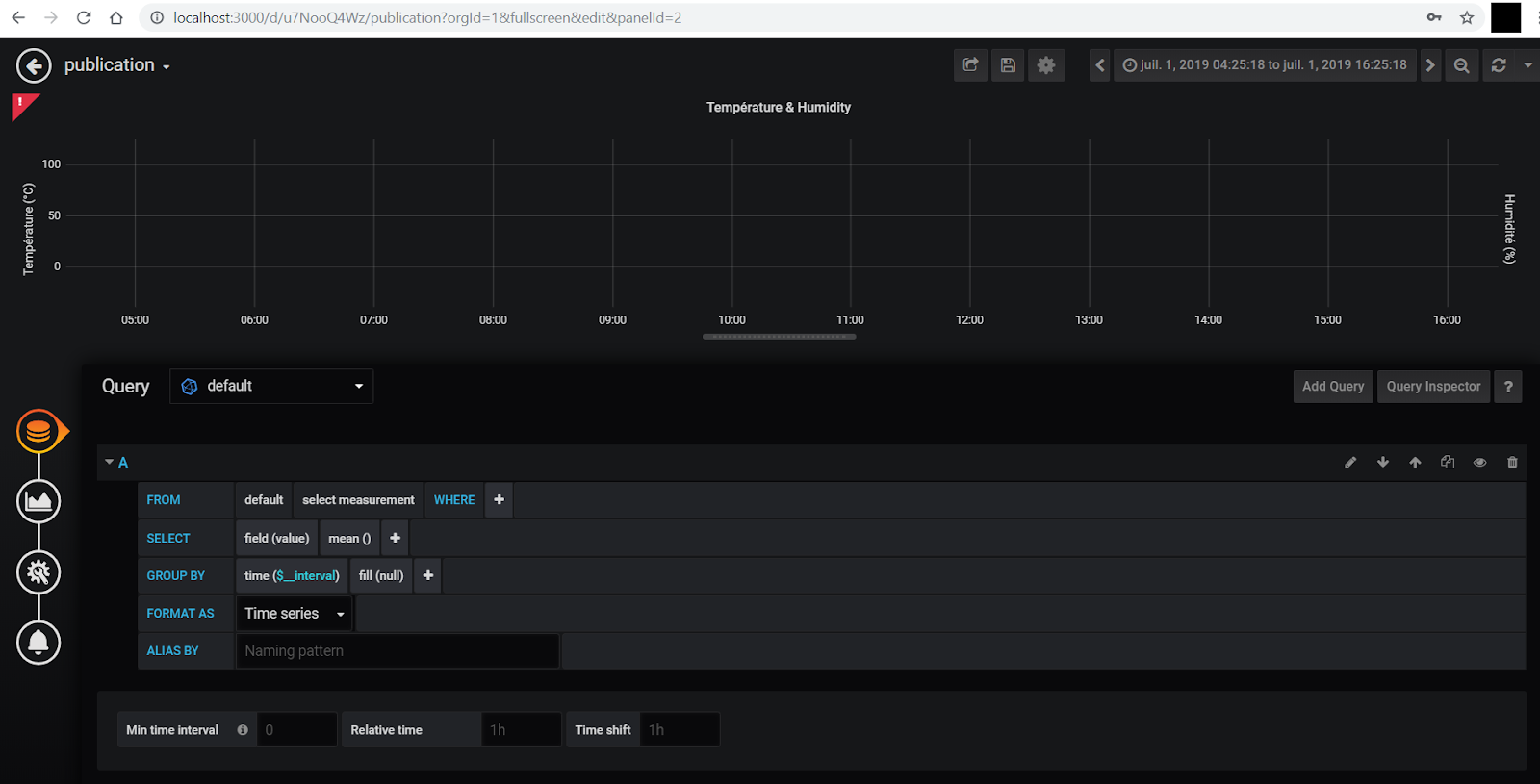
Maintenant, il ne nous reste plus qu’à sélectionner la Base De Données que l’on vient d’ajouter pour cela, on va cliquez sur la case associée à « Queries » :
On sélectionne « InfluxDB » puis on choisi dans « select measurement » le nom de la « measurement » soit l’équivalent d’une table en SQL.Sur la ligne « SELECT », cliquez sur le contenu des parenthèses de « field(value) », choisissez la température pour afficher les valeurs de température.
Sur la ligne « GROUP BY » ainsi que les suivantes, je vous conseille de ne pas toucher les valeurs qui s’y trouvent par défaut (à part « time() » dans les parenthèse de time où je vous conseille de sélectionner une valeur proche du temps de récupération de nos données, pour ma part j’ai sélectionné 5 minutes).
Maintenant que nous avons la température, appuyez sur le « + » de la ligne « SELECT » et choisissez dans « Fields », « field ».
Choisissez l’humidité et non pas la température car nous affichons déjà.
Maintenant, on shouhaite mettre l’humidité sur l’axe Y de droite. Pour cela, on va cliquer sur la couleur correspondante à l’humidité dans notre légende.
Sélectionnez « Y-Axis » puis activez « use right y-axis » et voilà notre humidité et attribué à l’axe des Y de droite.
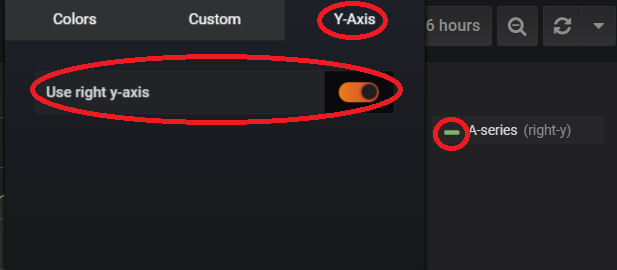
Nous avons notre graphique qui contient nos 2 valeurs afin de voir l’évolution des 2 simultanément q(ui permettra par exemple de soupçonner un orage qui se prépare).
Nous allons faire un graphique pour chacune des 2 valeurs, pour ce faire, on sélectionne le logo du graphique en bâton avec un + tout en haut de votre page qui s’appelle « Add panel »

On choisit comme précédemment « Choose Visualization », puis « Graph ».
On sélectionne les attributs qui nous convienne le mieux. Ici, je vais choisir en bâton.
On peut désactiver la colonne de droite car on aura qu’une seule variable cette fois ci dont un seul axe Y nécessaire donc on peut décocher « show » qui est dans la colonne « Right Y ».
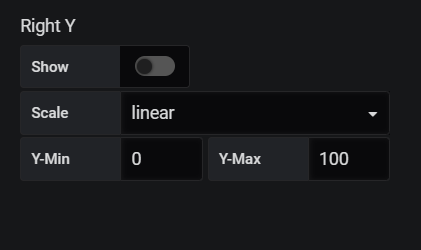
On redonne un titre à notre axe Y de gauche.
Dans general, on peut donner un titre à notre graphique (par exemple mettre « Température » et pour le prochain graphique contenant que l’humidité ne mettre que « Humidité » et pour notre 1er graphique on peut mettre « Température & Humidité »).
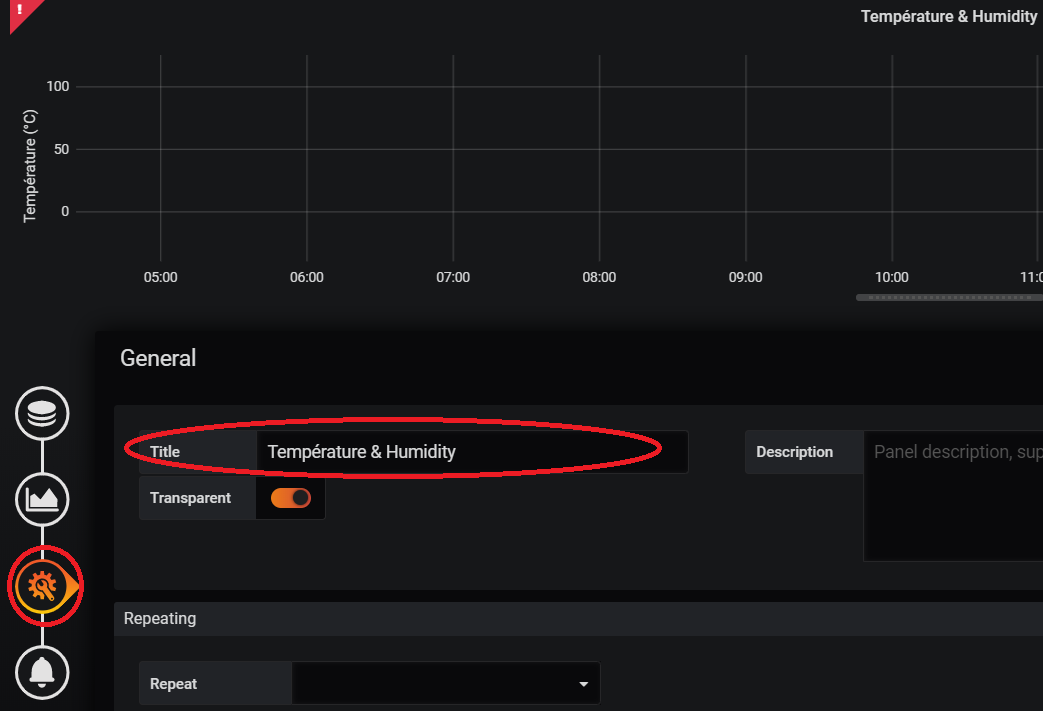
Allons dans la partie « Query » et sélectionnons encore une fois les valeurs qui nous intéressent.
Maintenant que cela est fait, appuyez sur la flèche en haut à gauche pour revenir à votre dashboard.
Répétez les mêmes opérations pour récupérer les données de l’humidité.
Désormais vous avez 3 graphique, un en « Line » pour récupérer les valeurs de l’humidité et de la température simultanément et 2 en « Bars ».
Maintenant, je vous propose de construire 2 « Gauges » qui nous permettront de voir les valeurs reçues en temps réels tout en implémentant un code couleurs en fonction de la température par exemple.
Il faudra pour cela cliquer sur « Add panel » puis de choisir encore une fois « Choose Visualization », cette fois-ci on va choisir « Gauge », plusieurs nouvelles variables font leur apparition mais ne vous inquiétez pas, cela sera rapide à régler.
Pour régler ce nouveau type de graphique, on va changer la valeur contenue dans « Calc » pour choisir « Last » ce qui nous permettra d’obtenir la dernière valeur obtenue.
Ensuite je vous conseille d’activer l’option « Labels » pour avoir les valeurs flottantes autour des zones que vous allez ajouter par la suite.
Pour la température, il faudra choisir l’unité « temperature » en degrés Celsius (°C) et pour l’Humidité, il faudra aller dans Misc et choisir « Humidity (%H) », pour la température, on peut changer les extremums pour mettre -40 et 120 et pour l’humidité on peut les laisser par défaut entre 0 et 100.
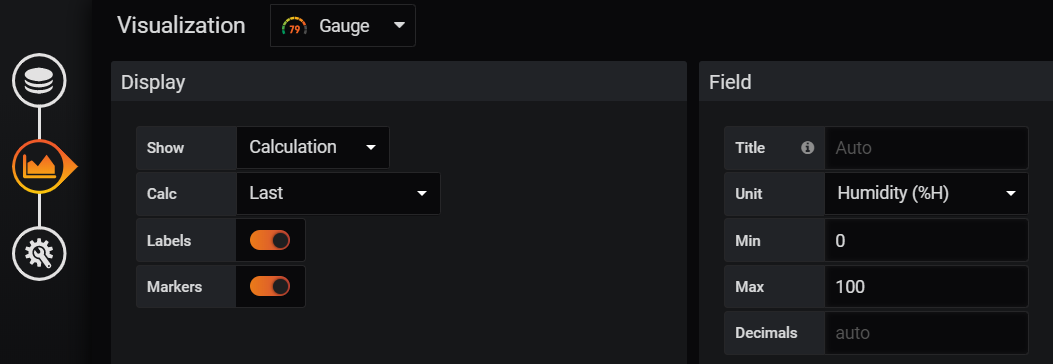
Ensuite, dans la colonne « Thresholds », vous pouvez ajouter des différentes couleurs et différentes valeurs permettant de faire varier la couleur comme on peut le voir ci-dessous par exemple :


Maintenant faite de même pour l’humidité ou la température en fonction de votre premier « Gauge ».
Une fois cela fait, il ne nous reste plus qu’une seule chose à faire.
Cliquez sur « Dashboard settings » (le petit engrenage tout en haut de votre page web).

La ligne « auto-refresh » possède plusieurs valeurs, vous pouvez toutes les supprimer et mettre 5min pour notre exemple.

Vous pouvez évidemment adapter cette valeur à votre guise( plus le temps sera court, plus cela consomme de la puissance, plus ce dernier aura les valeurs à jours et les plus récentes). Il ne vous reste plus qu’à sauvegarder.
Vous voilà prêt à visualiser et exploiter toutes vos données !
PARTIE 10: INSTALLATION DANS LA SERRE
Pour ma part, j’ai rangé la Lopy dans une boîte en plastique adaptée à ce genre d’usage ce qui permet de la protéger des intempéries et de l’humidité tout en laissant le capteur à l’extérieur comme son rôle le demande.


J’espère que ce tutoriel vous sera utile et il peut être adapté à tous les capteurs pour une serre, (pH, température eau,…)
Bonne continuation,
Sylvain Mazzoleni


[…] (Miniprojet 2019) Sylvain, Monitoring d’une serre, du capteur jusqu’au serveur via le trio LoRa, InfluxDB, Grafana http://miniprojets.net/index.php/2019/07/23/monitoring-dune-serre-du-capteur-jusquau-serveur/ […]
[…] Monitoring d’une serre, du capteur jusqu’au serveur via le trio Lora, InfluxDB, Grafana […]